TL;DR
This post is Part 1 of a series that covers strategic considerations for managing high-scale, high-performance data pipelines and security infrastructure. Part 2 dives into specific functionality with more tactical details and scenarios. Part 3 wraps up with a list of common pitfalls and how to avoid them.
–
Today’s SecOps leaders know that security engineering allows you to manage detection and response programs like high-performance software. Automation is the name of the game.
“The center of gravity for a modern SOC is automation.”
Anton Chuvakin, leading security and log management expert, from WTH Is Modern SOC
What might not be immediately clear is that high-performance security engineering depends heavily on high-performance data pipelines, powered by high-scale infrastructure.
High-fidelity detections, alerts, and investigations start with data quality. Focusing on signal-rich log sources ensures effectiveness and reduces total cost of ownership (TCO), but it requires more nuanced data pipelines.
Advanced data pipelines weren’t always a priority. Legacy SIEMs like Splunk initially had far fewer data points to collect, so aggregating everything into a single pane of glass for correlation, detection, and reporting made sense. The SIEM monolith model evolved from this backdrop.

This monolithic approach broke down as the number of sources generating security telemetry skyrocketed. The rapid expansion of applications, hosts, and infrastructure over the past decade put the SIEM monolith’s shortcomings under the microscope.
A single pane of glass stops making sense when it’s so densely packed with data that your team doesn’t know what they’re looking at, let alone what to do with it. Even if you could detangle all the data, it would cost a fortune with legacy SIEM licensing models.
Today the SIEM monolith is fading in favor of modular building blocks that enable efficient and performant ingestion, detection, and investigation workflows.
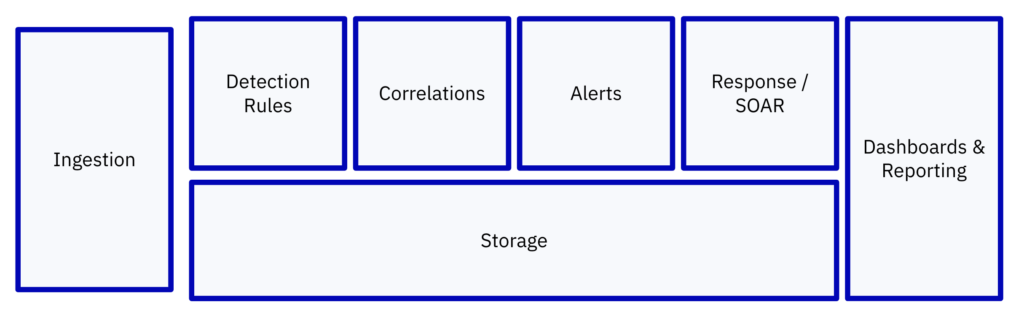
This starts with refactoring data pipelines for the flexibility needed to maximize alert fidelity, ensure consistent performance, and keep infrastructure costs low. Aligning people, process, and technology to make it all happen is easier said than done. Beginning by carefully reviewing a few strategic considerations points the way forward.
Some foundational considerations for your data pipeline, infrastructure, and detection strategy to get you started on the right path are detailed below.
First thing’s first: what is your budget? If you’re moving from a legacy SIEM, your budget is probably already under scrutiny. If you’re starting from scratch, you’ve likely bootstrapped your team to get this far, and your budget is unlikely to suddenly double.
The technology required to implement your strategy is your primary cost center. Expect to see vendors pricing based on a few standard parameters:
Whether it’s a hosted or on-premise deployment impacts how these charges show up. Different vendors structure their pricing with varying levels of detail and transparency, and add-ons increase the complexity. But under the hood, these three categories are the key cost drivers.
The key point: low value data costs as much as signal-rich, high-value data, reiterating the importance of being choosy about your data sources. Prioritizing high-value data creates a virtuous feedback loop of increased data quality leading to higher fidelity detections.
Being choosy about your data means answering which sources are the highest priority. This depends on a strong working knowledge of your infrastructure, applications, and endpoints. A firm grasp of emerging threats and relevant tactics techniques and procedures (TTPs) is also key.
Some categories to consider for prioritization might include:
It’s also important to get an idea of two related components – data formats and volumes:
Logs containing sensitive information will generally merit higher prioritization. This includes:
Some categories of telemetry data are clearly signal rich. Logs from critical resources indicating high-severity attacker TTPs provide immediate value. Some are not likely to generate high-fidelity detections alone, but their value becomes clear with correlation. Other sources are not valuable for detections but may be required for compliance or training threat models.
So you can think of 3 categories based on the data’s relevance to your detection and analysis workflows, and which storage is required:
When categorizing logs into these buckets, it’s helpful to consider things like:
You should also get a sense of the relative volumes in each bucket. If you’re like most organizations, you’ll find you have a smaller subset for immediate and near-term vs. historical analysis. And that’s good news, because hot and warm storage are more costly.
This reiterates the benefits of transitioning from monolithic SIEM to modular building blocks. Decoupling security data acquisition, analysis, and storage enables agility and efficiency. Your pipelines can feed into infrastructure with varying levels of performance to meet the use case’s requirements.
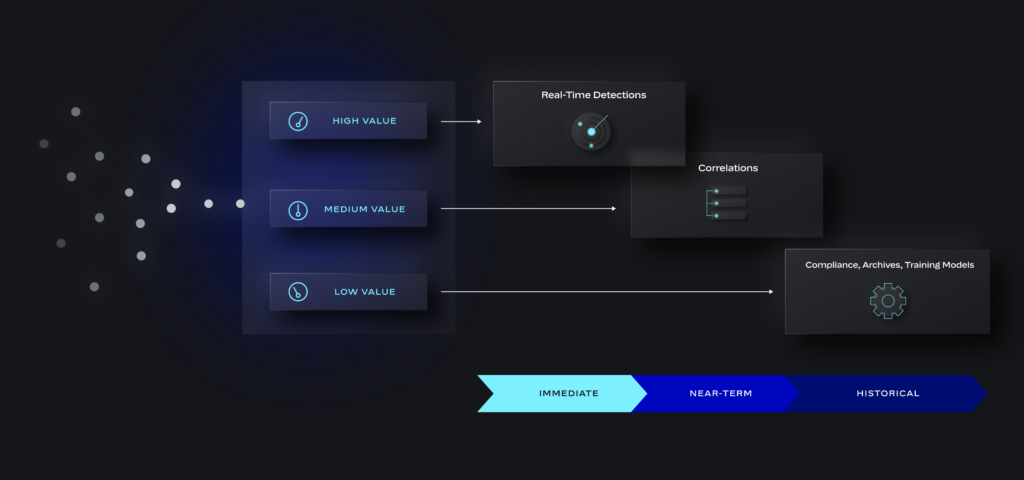
Immediate and near-term data aligns with higher performance compute and higher availability storage for high-fidelity detections. Historical data goes to low-cost storage: it’s there if you need it later, but it’s not slowing your team down and eating up budget. Say goodbye to bloated SIEM architectures and their super-sized bills. Say hello to lean, agile SecOps and drastic reductions in total cost of ownership
These timeframes help align your strategy to key functional requirements for your data pipeline workflows and infrastructure… which is where we’ll pick up in part 2. Stay tuned!
In the meantime, if you’d like to see how Panther enables high-scale ingestion pipeline workflows, request a demo.