TL;DR Cost-effective ingestion of noisy GuardDuty logs requires investment in filtering, enrichment, tuning, and a cloud-native SIEM that eliminates infrastructure management overhead and outmoded licensing fees.
Cybersecurity professionals know that visibility is foundational to security. Quite plainly, how can you spot malicious activity if you can’t see what’s going on? But gaining system visibility at cloud-scale is not without its challenges: cloud providers like AWS generate voluminous logs that can break budgets and clog up the threat detection environment.
In this blog, you’ll dig into AWS GuardDuty logs to understand why you should be ingesting them into your Security Information and Event Management (SIEM) platform, and how you can manage these “noisy” logs to control costs and improve detection. With this in mind, you’ll learn how to filter raw log data to only ingest relevant security information and boost your signal-to-noise ratio with log enrichment and detection-as-code. You’ll also understand the limitations of SIEM infrastructure and licensing that may prevent you from cost-effective ingestion.
Amazon GuardDuty is a security monitoring service that uses threat intelligence feeds and machine learning to identify unexpected, potentially unauthorized, and malicious activity within your AWS environment. Examples include identifying anomalous behavior like unusual API calls, deployments, or network traffic. When GuardDuty identifies suspicious activity, it records the activity as a security finding within the GuardDuty console or another AWS integration.
Notably, GuardDuty is a security solution for AWS resources only. That’s why practitioners who secure a multi or hybrid cloud environment use a SIEM to ingest GuardDuty logs alongside other log sources to monitor their entire attack surface on one platform. With a SIEM, practitioners have granular control over aggregating, normalizing, analyzing, and correlating logs—across all log sources—to comprehensively identify and address threats.
While log monitoring is ubiquitous in cybersecurity, the nature and structure of logs is not, which is why log management is necessary. This practice includes normalizing, analyzing, and storing logs to render them useful. With particularly voluminous AWS logs, log management becomes vital. Left unmanaged, noisy AWS logs create two major problems.
The first problem is about budget constraints. The high volume of AWS GuardDuty logs can lead to prohibitive ingestion costs, forcing an impossible choice: increase the budget, or don’t ingest at all. While more logs always require greater storage capacity, a big culprit driving up spending is traditional SIEM infrastructure and licensing structures that are unfriendly to high-volume cloud logs.
To maintain a baseline of performance, traditional SIEMs require ongoing database management to adjust how logs are indexed based on the write frequency and hardware profile. Then, there’s the high price of hot storage causing most data to reside in warm and cold buckets that take much longer to query during incident response and threat hunting. Facing these obstacles on top of additional licensing fees for cloud logs, security teams often do not ingest GuardDuty logs into their SIEM, but resort instead to siloing their log data in an S3 bucket, if at all.
The second problem is about threat detection. Any number of irrelevant logs ingested into your SIEM congests the threat detection environment. Congestion contributes to well-known operational issues that increase risk, including alert fatigue, false positives, and slow mean time to resolve (MTTR). A prime example of the impact of alert fatigue on effective threat detection is the March 2023 attack on 3CX’s supply chain.
If you are still using a traditional SIEM, migrating to a cloud-based SIEM will have the most significant impact on your ability to cost-effectively ingest AWS logs and gain full system visibility.
Here’s why: a cloud-based SIEM leverages serverless architecture to eliminate infrastructure management; further, log data is saved in a security data lake that uses modern cloud database technology designed to not only handle cloud-scale data, but guarantee query performance. This enables cloud-based SIEM platforms to deliver exactly what modern security teams need:
Short of adopting a cloud-native SIEM, controlling noisy log data requires investment in filtering, a key log management practice. There are a few ways to create filters, depending on how your log pipeline is set up.
Within AWS, you can create GuardDuty finding filters that only report findings that match with your specified criteria. Unmatched findings are ignored and thrown out. You can also implement GuardDuty suppression rules to automatically archive findings that match the specified criteria. AWS recommends using suppression rules to “filter low-value findings, false positive findings, or threats you do not intend to act on,” reducing overall noise.
However, if your log pipeline uses AWS CloudWatch to aggregate and forward logs, you may prefer to use subscription filters to control which logs are sent to your SIEM.
Within your SIEM, you can create filters by log source to ignore—or throw out—log data before it’s analyzed for threats and saved to your data lake. Two common methods are raw data filters and normalized data filters.
A raw data filter processes and filters log data before the SIEM normalizes the data according to its schemas. A raw data filter specifies a pattern to match with. If any log matches the pattern, the entire log is ignored and not processed by the SIEM. The available tools for filtering raw log data depends on the SIEM you are working with, but these are the two most common methods:
In contrast, a normalized data filter processes and filters log data after the SIEM normalizes the data. The benefit here is a granular filter that can throw out individual fields—or “keys”, pieces of data within a log—instead of the entire log.
To create a normalized data filter, you’ll typically need the following information:
With both filtering methods, any logs that are dropped during the filtering process should not contribute to your overall ingestion quota; verify pricing with your SIEM vendor.
Filtering starts by determining what information is irrelevant to security. Let’s look at an example of how to use a substring filter to exclude sample GuardDuty findings.
AWS GuardDuty assigns a severity level to all its findings, and it’s common to create detections that target these categories:
For testing purposes, you can generate sample GuardDuty findings. Like real findings, sample findings will also have severity levels assigned. To distinguish sample data from actual data, GuardDuty includes the value “sample”: true within the log data. Within your SIEM, you can use that exact text—”sample”: true—as a substring filter to exclude all sample data from being ingested into your SIEM.
Using GuardDuty finding filters, you need to specify filter criteria for what you want to surface: you’ll create a filter with the attribute sample set to the value false. With this finding filter, you’ll only see actual data and filter out any sample data.
With a GuardDuty suppression rule, do the opposite: create a filter with the attribute sample set to value true, in order to filter out all sample data.
Alongside filtering, enriching your log data with context and threat intelligence increases the fidelity of your alerts and speeds up investigation and incident response. A classic example is adding information about business assets to log data, like a user-to-hardware mapping. Another example is mapping numeric IDs or error codes to human readable information.
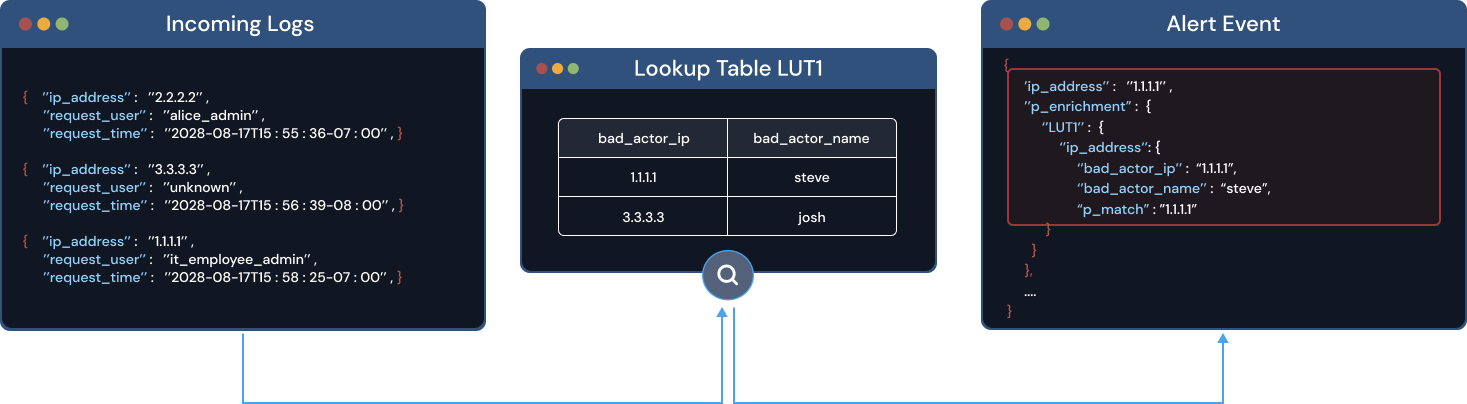
To enrich logs, create a lookup table, a custom data set that you upload to your SIEM and configure to enrich one or more specified log types. The next image shows how this process works, where a lookup table of known bad actors enriches an incoming log by the matching IP address 1.1.1.1.
Your SIEM may also partner with third-party threat intelligence providers for out-of-the-box log enrichment. For example, IPInfo is a threat intelligence provider that compiles IP address data, like geolocation. With IPInfo you can preemptively identify and block traffic from high-risk locations or networks.
Filtering enables you to reduce noise and control cost, and log enrichment improves the fidelity of your alerts. But another essential task is to increase your signal-to-noise ratio by tuning detections.
Tuning detections is the process of customizing detections so they are optimized for your specific environment, address emerging threats, and cover any security gaps. When detections are specific, informative, and cover relevant security threats, you’ll be able to more accurately identify threats and resolve them faster. In other words, you’ll clearly hear the signal amid the noise.
Boosting signal-to-noise has important downstream effects on your operations and cost: it reduces alert fatigue, false positives, and false negatives, and it improves mean time to detect (MTTD); practitioners can get out from the endless cycle of responding to alerts, and spend more time tuning detections, creating a positive feedback loop.
But the ability to customize detections varies across SIEMs. It’s well known that legacy SIEMs suffer from inflexible tools that limit the extent to which you can tune and optimize detections for your environment. Platforms that offer detection-as-code (DaC) are taking customization and flexibility to a whole new level, by writing, managing, and deploying detections through code. The drive behind DaC is to make threat detection consistent, reliable, reusable, and scalable, all while controlling cost.
First, get a sense of what a code-based detection looks like. Check out the next image that shows an excerpt from a Python detection for high severity GuardDuty events. This is one of Panther’s 500+ pre-built detections. The logic in this rule will trigger an alert when the log data contains a “severity” key with a value between 7.0 and 8.9. What’s not shown in this excerpt is the logic that defines what information goes into the alert, tests for the detection, and other ways to customize how and when the alert is triggered.

Now let’s connect the dots and understand how DaC’s core features give you the customization and flexibility to optimize your threat detection environment, and your operations:
To summarize, detection-as-code is all about efficiency and reliability; it gives security practitioners the flexibility to optimize their detections and the agility to stay on top of threats in an ever-changing cybersecurity landscape. To get a closer look at DaC, including no-code workflows, read how to create a code-based detection.
Traditional SIEMs cannot keep pace with cloud workloads, sacrificing timely and cost-effective service, and increasing overall vulnerability. Whether you control cost and noise with filtering, or boost your signal-to-noise ratio with detection-as-code, choose a SIEM that is built to handle cloud-scale data, without compromise.
Take a deep dive on how to keep AWS logs from running wild with Panther, a cloud-native SIEM that’s built for AWS. Panther empowers modern security teams with real-time threat detection, log aggregation, incident response, and continuous compliance, at cloud-scale.
Ready to try Panther? Get started by requesting a demo.