This is part 2 of our 3-part series on managing pipelines and infrastructure for high-fidelity detections. Part 1 outlined strategic considerations, and this post drills into functional requirements. Part 3 will wrap up with common pitfalls and how to avoid them.
So you’ve considered cost, priority logs, data formats, volumes, and time frames. Now it’s time to evaluate specific requirements. Using pipeline functionality to streamline SecOps is a great example of the “shift left” engineering philosophy at work. And while routing, filtering, and transformation seem basic, these challenges have dogged security teams for two decades.
“One of the most notorious and painful problems that has amazing staying power is of course that of data collection.”
– Anton Chuvakin, leading security and log management expert, from “20 Years of SIEM”
So where to start? How can you filter noisy components from critical high volume logs to reduce data volume and ensure data quality? What routing functionality do you need to move different logs to appropriate locations for processing and storage? What formats are your logs in–standardized, lightweight formats like JSON, or nonstandard formats from custom systems?
Maybe your use cases require a combination of filtering, routing, and transformation capabilities. How do they need to interact to achieve your goals? Developing evaluation criteria around these questions will narrow down which vendors and technical approaches can power your strategy. As that evaluation comes together, you’ll want to build specific tactical processes into your plan.
Routing functionality helps balance performance and cost by allowing you to manage the flow of data so it aligns to more efficient infrastructure.
Part one covered how different time frames require different analysis and storage capabilities. Routing makes these scenarios possible. Sending high value security data to hot storage for immediate analysis ensures rapid detection of emerging threats. Routing moderate value data to warm storage supports correlations to pinpoint more complex attacks. Routing low value data to cold storage ensures you’re prepared to fulfill compliance reporting obligations with minimum costs.
Other routing scenarios depend on the environment and use cases. If you have high priority logs that spike at specific times, routing to different processing clusters can help balance the load and maintain performance. For international organizations, routing different regional data sources to separate destinations enables nuanced analysis based on local threat models. It also streamlines compliance reporting for different jurisdictions.
Filtering is all about dropping the noise and amplifying the signals. Perhaps a more familiar metaphor than gold panning: the proverbial needle in a haystack. How do you make it easier to find that needle? Collect less hay. The benefits of filtering include:
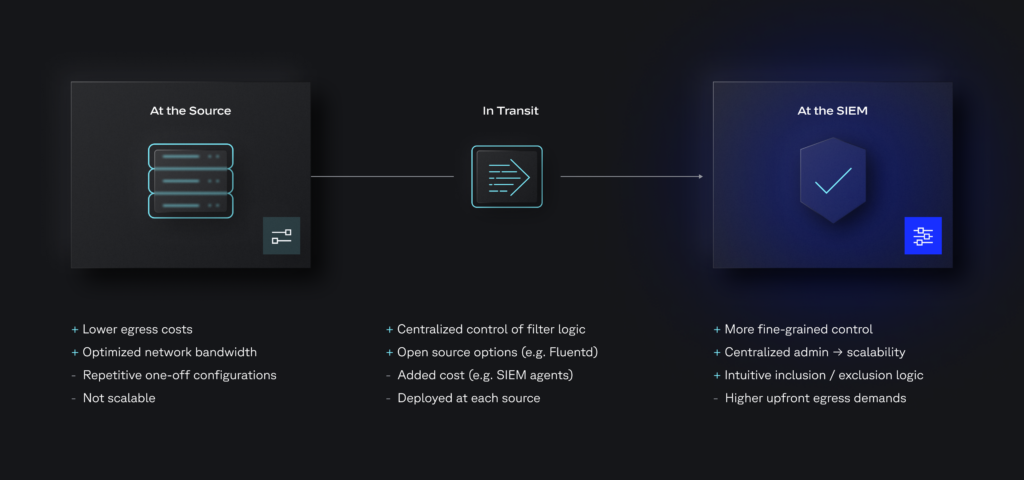
You have a few options when determining where to filter. Each comes with its own technical implications and pros and cons:
Specific requirements for which logs and log components to filter depend on your threat model, but it’s a safe bet to start with high volume logs. Many SIEMs offer canned reports on volume by source, which can help identify logs that would benefit from filtering. Sources like cloud network infrastructure and key management services generate very high volumes, and not all of it is critical.
Some other filtering considerations are listed below:
Below are more specific examples of logs that are generally OK to filter:
Transformation increases the security value of your data by normalizing it into a standard format that aligns with your analysis logic. The result: faster detections and streamlined investigations.
Below is a run down of various transformation processes and how they apply to common security workflows:
That covers the how for transformations. Another consideration is when, which goes back to the previously discussed time frames:
Optionality between schema on read vs schema on write for different threat scenarios and time frames gives you flexibility to ensure your detections are effective while keeping TCO low.
Now that we’ve covered detailed tactical considerations, let’s put on our security engineer hat and dig into a couple example scenarios.
Situation: I want to be alerted when an unexpected port opens on a server, as this event could indicate a malware exploit, unauthorized access, or other security threat. Netstat is configured to monitor the server. Fluent bit is collecting, aggregating, and forwarding the logs, which include netstat’s command headers. Noisy data in the headers is resulting in classification failures: the property my Netstat schema expects is an integer value, but instead it receives a string.
Action: The netstat command data is not relevant to my detections, so it’s a perfect candidate for filtering. I set up two Raw Event Filters in order to simply filter out the events that are being captured as addresses by my Schema, before impacting the processing bandwidth of my system.
Result: Classification failures that were originating due to the noisy netstat command headers are now resolved. By filtering out the noise, my detections on unexpected port activity are working as expected, and I’m able to validate that I’ll be alerted in the event of an exploit. I’ve improved the overall data quality in my SIEM.
Situation: I’m still monitoring for unexpected ports opening. Inbound logs frequently have an “address” property that includes information for both port and IP address. With this combined field, my detection rules must include logic to separate out the port information, and having to perform this analysis for each detection is beginning to slow down performance.
Action: I write a Starlark script into my schema, that at ingestion time will perform a split transformation of the incoming address property. This separates the combined “address” field into separate “port” and “IP” fields to support more granular analysis.
Result: Now my detection logic can be simplified to just identify whether an open port exists, without extra steps to identify the port attribute within the combined address field. This transformation improves the speed and overall performance of my detections, making it easier to monitor for unexpected port openings. It also streamlines query logic to search for activity related to the port.
Situation: Port 47760 is used by Zeek which is running on my servers in order to monitor them. That port is expected to be open on all my production servers since they have Zeek installed. Due to budget constraints I want to filter them out.
Action: I set up a Normalized Event Filter that excludes log data on port 47760. Since this information is no longer included in ingested data, I’m able to simplify my Detection by removing these two ports from the list of the expected ports in the detection logic.
Result: Filtering out this low-value data has reduced costs by decreasing the overall volume of data being ingested. Furthermore, simplifying the logic in my detections by excluding these common ports helps improve the fidelity and speed of my detections and alerts, making it easier to identify and respond to potential security threats on other, less commonly used ports.
Between your priority logs and the combinations of routing, filtering, and transformation capabilities your use cases require, there are practically infinite security pipeline scenarios.
If data is the new gold, striking it rich with security insight requires some mining. So regardless of what your project requires, the pipeline processes and functionality you implement will go a long way in determining the overall success of your SecOps program.
If you’re interested in how Panther can power your high-scale ingestion pipeline workflows with parsing, normalization, filtering, and transformations, request a demo.