Introduction
With the recent proliferation of npm malware, from the NX compromise to the Sha1-Hulud self-propagating worms, software registry supply chain attacks continue to be a major threat to developers and organizations. To keep up with the rapid evolution of these threats, Panther’s threat research team built a scanner to detect malicious software packages as they are published. This steady stream of high-fidelity data has already proved very useful in analyzing the second wave of Sha1-Hulud compromises Thanksgiving week, and continues to give us deep visibility into emerging threats in the npm ecosystem. This post digs into why we wanted to build our own scanner, how it’s architected for scale, and how we use Panther as a security research platform to analyze this data.
Why would you do this?
There are many commercial threat intelligence feeds for npm packages, from well-established vendors like Socket.dev and Aikido to newcomers like HelixGuard. Why bother building our own? The build vs. buy conversation is important in any circumstance, and in this case, a few considerations informed our decision to build.
Better understanding of the problem space. How the software supply chain ecosystem works and the challenges of processing data at scale.
Fine-grained control over what we consider malicious. The ability to add our own static analysis rules to test our hypotheses about threat actor behavior.
No black boxes. Most software supply chain threat feeds will tell you if a package is malicious, but not why the vendor deemed it so.
For Panther’s Threat Research Team, the choice to build was obvious.
Prototyping
The core functionality of the scanner can be described in the following pseudo-code:
With the help of a coding agent like Claude Code, I was able to spin up a Python prototype running locally on my laptop in a couple of hours. What I quickly learned is that the npm feed is a firehose. I could leave my computer running 24/7/365 and never hope to catch up with the constant deluge of node packages being published. There’s also a little thing called rate limiting that kept timing out my requests to the npm metadata API. In a simple for loop like the one described in the pseudo-code, one rate limit timeout would cause the whole process to grind to a halt. I would need error handling, retries, exponential backoff, persistent state…
Scaling up
Rather than solving any of those problems, I had an epiphany: loops are an anti-pattern. At this volume, everything needs to happen simultaneously, in parallel, to have any hope of keeping up. Instead of making every request from a single IP and rolling my own exponential backoff mechanism, why not make every request from a different IP? Instead of adding error handling to the loop, why not just dump failed API calls into a retry queue and try again later? In fact, rather than looping at all, why not use an asynchronous pool of workers that scales up on demand as volume increases?

That’s when I learned about fan-out architecture, unique lambda IPs, and SQS queues. By migrating my prototype to AWS, I was able to eliminate the loop, never get rate-limited, and not write a single line of error handling. It works like this:
Fetcher lambda pulls the latest batch of newly published npm packages, keeping track of the last record pulled in a S3 checkpoint file
These records get dumped into an SQS queue, where they are picked up asynchronously by an Enricher lambda. Each lambda invocation processes a single npm package, meaning every request comes from a different AWS lambda IP
Enriched records for packages with install scripts (the primary attack vector for malicious code) get dumped into another SQS queue, where they are picked up by an auto-scaling ECS service running the static analysis rules. This step needs ECS instead of lambda because the scans can take longer than the 15 minute lambda timeout
From there, the static analysis results are passed through yet another SQS queue to a lambda that calls Claude 4.5 Haiku in Amazon Bedrock to perform AI-assisted malware analysis
Finally, the combined results are written to an S3 bucket, where they are ingested into Panther
If anything fails at any point, the record is re-queued into the previous SQS queue or a DLQ after several retries. The system scales up/down automatically as package publication volumes fluctuate. Each step filters out benign packages before passing them to the next, more processing-intensive step.
Feeding the Panther
Panther is the perfect platform for large-scale security research. We’re accustomed to parsing billions of security events an hour — a few thousand npm packages per day is a drop in the bucket. The datalake is excellent for searching and aggregating multiple packages across versions, authors, and malware campaigns. The alerting engine and AI alert triage make it easy to correlate related packages and analyze publication patterns over time.
{
"analysis": "This package is definitively malicious and represents a sophisticated credential theft operation. The analysis reveals multiple layers of malicious functionality:\n\n**Credential Extraction Capabilities**: The package exports functions for extracting Discord tokens (readLevelDBRaw, readLevelDBDirect, decryptDiscordDesktopStorage), Telegram session files (extractAllTelegramSessions, getTelegramSessionInfo), and cryptocurrency wallet keys (extractAllWalletKeys, extractWalletKeys). These functions target LevelDB databases used by Discord, Chrome, Brave, Edge, and Telegram Desktop to store authentication credentials.\n\n**Automated Exfiltration**: The postinstall script automatically executes bin/extract-tokens.js, which extracts credentials without user knowledge or consent. The package includes functions like sendTokenToTelegram, sendInviteToTelegram, and sendAllWalletsToTelegram that transmit stolen credentials to attacker-controlled Telegram bots.\n\n**Evasion Mechanisms**: The preinstall.js script contains aggressive anti-forensics and anti-detection code: (1) It kills all node.exe processes except npm to prevent interference, (2) It attempts to hide console windows using VBScript and Windows API calls, (3) It redirects stdout/stderr to prevent visibility, (4) It uses windowsHide and creationFlags to execute commands silently, (5) The security-bypass.js module adds the package directory to Windows Defender exclusions.\n\n**Obfuscation and Concealment**: The package uses high-entropy strings and binary file encoding to hide malicious code from static analysis. The preinstall script is intentionally complex and uses multiple execution methods (PowerShell, VBScript, taskkill, wmic) to maximize compatibility and evade detection.\n\n**Suspicious Package Metadata**: The package.json contains a circular dependency (github-badge-bot depends on github-badge-bot@1.11.7), which is a known technique to maintain persistence and complicate removal. The description claims to be a 'Discord bot that monitors servers and sends invite links via Telegram,' which is a cover story for the actual credential theft functionality. The package has no author, no repository link, and no legitimate documentation.\n\n**Installation-Time Execution**: The preinstall and postinstall hooks ensure malicious code executes during npm install before the user can inspect the package contents. This is a critical attack vector that bypasses normal security review processes.\n\n**Multi-Target Approach**: The package targets Discord, Telegram, Chrome, Brave, Edge, and cryptocurrency wallets, indicating a sophisticated attacker seeking maximum credential coverage. The inclusion of wallet extraction (extractAllWalletKeys, extractWalletKeys) suggests financial theft motivation.\n\n**Recent Publication**: The package was published 1 day ago with 8,616 downloads in the first week, indicating active distribution and potential compromise of many systems. The version number (1.15.1) suggests this is part of an ongoing campaign with multiple iterations.",
"confidence": 0.98,
"iocs": {
"commands": [
"taskkill /F /PID",
"wmic process where",
"cscript //nologo //e:vbscript",
"powershell -Command",
"node bin/preinstall.js",
"node bin/extract-tokens.js"
],
"file_paths": [
"~/.config/discord/Local Storage/leveldb",
"~/.config/google-chrome/Default/Local Storage/leveldb",
"~/.config/BraveSoftware/Brave-Browser/Default/Local Storage/leveldb",
"~/.config/microsoft-edge/Default/Local Storage/leveldb",
"~/.local/share/Telegram Desktop",
"~/.config/Telegram Desktop",
"AppData/Local/Discord/Local Storage/leveldb",
"AppData/Local/Google/Chrome/User Data/Default/Local Storage/leveldb",
"AppData/Local/BraveSoftware/Brave-Browser/User Data/Default/Local Storage/leveldb",
"AppData/Local/Microsoft/Edge/User Data/Default/Local Storage/leveldb",
"AppData/Roaming/Telegram Desktop",
"node_modules/github-badge-bot"
],
"other": [
"bin/extract-tokens.js",
"bin/preinstall.js",
"lib/token-extractor.js",
"lib/telegram-extractor.js",
"lib/wallet-extractor.js",
"lib/security-bypass.js",
"lib/discord-desktop-decrypt.js",
"Telegram Bot API integration for credential exfiltration",
"Windows Credential Manager access",
"LevelDB database extraction from browsers and Discord"
]
{
"analysis": "This package is definitively malicious and represents a sophisticated credential theft operation. The analysis reveals multiple layers of malicious functionality:\n\n**Credential Extraction Capabilities**: The package exports functions for extracting Discord tokens (readLevelDBRaw, readLevelDBDirect, decryptDiscordDesktopStorage), Telegram session files (extractAllTelegramSessions, getTelegramSessionInfo), and cryptocurrency wallet keys (extractAllWalletKeys, extractWalletKeys). These functions target LevelDB databases used by Discord, Chrome, Brave, Edge, and Telegram Desktop to store authentication credentials.\n\n**Automated Exfiltration**: The postinstall script automatically executes bin/extract-tokens.js, which extracts credentials without user knowledge or consent. The package includes functions like sendTokenToTelegram, sendInviteToTelegram, and sendAllWalletsToTelegram that transmit stolen credentials to attacker-controlled Telegram bots.\n\n**Evasion Mechanisms**: The preinstall.js script contains aggressive anti-forensics and anti-detection code: (1) It kills all node.exe processes except npm to prevent interference, (2) It attempts to hide console windows using VBScript and Windows API calls, (3) It redirects stdout/stderr to prevent visibility, (4) It uses windowsHide and creationFlags to execute commands silently, (5) The security-bypass.js module adds the package directory to Windows Defender exclusions.\n\n**Obfuscation and Concealment**: The package uses high-entropy strings and binary file encoding to hide malicious code from static analysis. The preinstall script is intentionally complex and uses multiple execution methods (PowerShell, VBScript, taskkill, wmic) to maximize compatibility and evade detection.\n\n**Suspicious Package Metadata**: The package.json contains a circular dependency (github-badge-bot depends on github-badge-bot@1.11.7), which is a known technique to maintain persistence and complicate removal. The description claims to be a 'Discord bot that monitors servers and sends invite links via Telegram,' which is a cover story for the actual credential theft functionality. The package has no author, no repository link, and no legitimate documentation.\n\n**Installation-Time Execution**: The preinstall and postinstall hooks ensure malicious code executes during npm install before the user can inspect the package contents. This is a critical attack vector that bypasses normal security review processes.\n\n**Multi-Target Approach**: The package targets Discord, Telegram, Chrome, Brave, Edge, and cryptocurrency wallets, indicating a sophisticated attacker seeking maximum credential coverage. The inclusion of wallet extraction (extractAllWalletKeys, extractWalletKeys) suggests financial theft motivation.\n\n**Recent Publication**: The package was published 1 day ago with 8,616 downloads in the first week, indicating active distribution and potential compromise of many systems. The version number (1.15.1) suggests this is part of an ongoing campaign with multiple iterations.",
"confidence": 0.98,
"iocs": {
"commands": [
"taskkill /F /PID",
"wmic process where",
"cscript //nologo //e:vbscript",
"powershell -Command",
"node bin/preinstall.js",
"node bin/extract-tokens.js"
],
"file_paths": [
"~/.config/discord/Local Storage/leveldb",
"~/.config/google-chrome/Default/Local Storage/leveldb",
"~/.config/BraveSoftware/Brave-Browser/Default/Local Storage/leveldb",
"~/.config/microsoft-edge/Default/Local Storage/leveldb",
"~/.local/share/Telegram Desktop",
"~/.config/Telegram Desktop",
"AppData/Local/Discord/Local Storage/leveldb",
"AppData/Local/Google/Chrome/User Data/Default/Local Storage/leveldb",
"AppData/Local/BraveSoftware/Brave-Browser/User Data/Default/Local Storage/leveldb",
"AppData/Local/Microsoft/Edge/User Data/Default/Local Storage/leveldb",
"AppData/Roaming/Telegram Desktop",
"node_modules/github-badge-bot"
],
"other": [
"bin/extract-tokens.js",
"bin/preinstall.js",
"lib/token-extractor.js",
"lib/telegram-extractor.js",
"lib/wallet-extractor.js",
"lib/security-bypass.js",
"lib/discord-desktop-decrypt.js",
"Telegram Bot API integration for credential exfiltration",
"Windows Credential Manager access",
"LevelDB database extraction from browsers and Discord"
]
{
"analysis": "This package is definitively malicious and represents a sophisticated credential theft operation. The analysis reveals multiple layers of malicious functionality:\n\n**Credential Extraction Capabilities**: The package exports functions for extracting Discord tokens (readLevelDBRaw, readLevelDBDirect, decryptDiscordDesktopStorage), Telegram session files (extractAllTelegramSessions, getTelegramSessionInfo), and cryptocurrency wallet keys (extractAllWalletKeys, extractWalletKeys). These functions target LevelDB databases used by Discord, Chrome, Brave, Edge, and Telegram Desktop to store authentication credentials.\n\n**Automated Exfiltration**: The postinstall script automatically executes bin/extract-tokens.js, which extracts credentials without user knowledge or consent. The package includes functions like sendTokenToTelegram, sendInviteToTelegram, and sendAllWalletsToTelegram that transmit stolen credentials to attacker-controlled Telegram bots.\n\n**Evasion Mechanisms**: The preinstall.js script contains aggressive anti-forensics and anti-detection code: (1) It kills all node.exe processes except npm to prevent interference, (2) It attempts to hide console windows using VBScript and Windows API calls, (3) It redirects stdout/stderr to prevent visibility, (4) It uses windowsHide and creationFlags to execute commands silently, (5) The security-bypass.js module adds the package directory to Windows Defender exclusions.\n\n**Obfuscation and Concealment**: The package uses high-entropy strings and binary file encoding to hide malicious code from static analysis. The preinstall script is intentionally complex and uses multiple execution methods (PowerShell, VBScript, taskkill, wmic) to maximize compatibility and evade detection.\n\n**Suspicious Package Metadata**: The package.json contains a circular dependency (github-badge-bot depends on github-badge-bot@1.11.7), which is a known technique to maintain persistence and complicate removal. The description claims to be a 'Discord bot that monitors servers and sends invite links via Telegram,' which is a cover story for the actual credential theft functionality. The package has no author, no repository link, and no legitimate documentation.\n\n**Installation-Time Execution**: The preinstall and postinstall hooks ensure malicious code executes during npm install before the user can inspect the package contents. This is a critical attack vector that bypasses normal security review processes.\n\n**Multi-Target Approach**: The package targets Discord, Telegram, Chrome, Brave, Edge, and cryptocurrency wallets, indicating a sophisticated attacker seeking maximum credential coverage. The inclusion of wallet extraction (extractAllWalletKeys, extractWalletKeys) suggests financial theft motivation.\n\n**Recent Publication**: The package was published 1 day ago with 8,616 downloads in the first week, indicating active distribution and potential compromise of many systems. The version number (1.15.1) suggests this is part of an ongoing campaign with multiple iterations.",
"confidence": 0.98,
"iocs": {
"commands": [
"taskkill /F /PID",
"wmic process where",
"cscript //nologo //e:vbscript",
"powershell -Command",
"node bin/preinstall.js",
"node bin/extract-tokens.js"
],
"file_paths": [
"~/.config/discord/Local Storage/leveldb",
"~/.config/google-chrome/Default/Local Storage/leveldb",
"~/.config/BraveSoftware/Brave-Browser/Default/Local Storage/leveldb",
"~/.config/microsoft-edge/Default/Local Storage/leveldb",
"~/.local/share/Telegram Desktop",
"~/.config/Telegram Desktop",
"AppData/Local/Discord/Local Storage/leveldb",
"AppData/Local/Google/Chrome/User Data/Default/Local Storage/leveldb",
"AppData/Local/BraveSoftware/Brave-Browser/User Data/Default/Local Storage/leveldb",
"AppData/Local/Microsoft/Edge/User Data/Default/Local Storage/leveldb",
"AppData/Roaming/Telegram Desktop",
"node_modules/github-badge-bot"
],
"other": [
"bin/extract-tokens.js",
"bin/preinstall.js",
"lib/token-extractor.js",
"lib/telegram-extractor.js",
"lib/wallet-extractor.js",
"lib/security-bypass.js",
"lib/discord-desktop-decrypt.js",
"Telegram Bot API integration for credential exfiltration",
"Windows Credential Manager access",
"LevelDB database extraction from browsers and Discord"
]
{
"analysis": "This package is definitively malicious and represents a sophisticated credential theft operation. The analysis reveals multiple layers of malicious functionality:\n\n**Credential Extraction Capabilities**: The package exports functions for extracting Discord tokens (readLevelDBRaw, readLevelDBDirect, decryptDiscordDesktopStorage), Telegram session files (extractAllTelegramSessions, getTelegramSessionInfo), and cryptocurrency wallet keys (extractAllWalletKeys, extractWalletKeys). These functions target LevelDB databases used by Discord, Chrome, Brave, Edge, and Telegram Desktop to store authentication credentials.\n\n**Automated Exfiltration**: The postinstall script automatically executes bin/extract-tokens.js, which extracts credentials without user knowledge or consent. The package includes functions like sendTokenToTelegram, sendInviteToTelegram, and sendAllWalletsToTelegram that transmit stolen credentials to attacker-controlled Telegram bots.\n\n**Evasion Mechanisms**: The preinstall.js script contains aggressive anti-forensics and anti-detection code: (1) It kills all node.exe processes except npm to prevent interference, (2) It attempts to hide console windows using VBScript and Windows API calls, (3) It redirects stdout/stderr to prevent visibility, (4) It uses windowsHide and creationFlags to execute commands silently, (5) The security-bypass.js module adds the package directory to Windows Defender exclusions.\n\n**Obfuscation and Concealment**: The package uses high-entropy strings and binary file encoding to hide malicious code from static analysis. The preinstall script is intentionally complex and uses multiple execution methods (PowerShell, VBScript, taskkill, wmic) to maximize compatibility and evade detection.\n\n**Suspicious Package Metadata**: The package.json contains a circular dependency (github-badge-bot depends on github-badge-bot@1.11.7), which is a known technique to maintain persistence and complicate removal. The description claims to be a 'Discord bot that monitors servers and sends invite links via Telegram,' which is a cover story for the actual credential theft functionality. The package has no author, no repository link, and no legitimate documentation.\n\n**Installation-Time Execution**: The preinstall and postinstall hooks ensure malicious code executes during npm install before the user can inspect the package contents. This is a critical attack vector that bypasses normal security review processes.\n\n**Multi-Target Approach**: The package targets Discord, Telegram, Chrome, Brave, Edge, and cryptocurrency wallets, indicating a sophisticated attacker seeking maximum credential coverage. The inclusion of wallet extraction (extractAllWalletKeys, extractWalletKeys) suggests financial theft motivation.\n\n**Recent Publication**: The package was published 1 day ago with 8,616 downloads in the first week, indicating active distribution and potential compromise of many systems. The version number (1.15.1) suggests this is part of an ongoing campaign with multiple iterations.",
"confidence": 0.98,
"iocs": {
"commands": [
"taskkill /F /PID",
"wmic process where",
"cscript //nologo //e:vbscript",
"powershell -Command",
"node bin/preinstall.js",
"node bin/extract-tokens.js"
],
"file_paths": [
"~/.config/discord/Local Storage/leveldb",
"~/.config/google-chrome/Default/Local Storage/leveldb",
"~/.config/BraveSoftware/Brave-Browser/Default/Local Storage/leveldb",
"~/.config/microsoft-edge/Default/Local Storage/leveldb",
"~/.local/share/Telegram Desktop",
"~/.config/Telegram Desktop",
"AppData/Local/Discord/Local Storage/leveldb",
"AppData/Local/Google/Chrome/User Data/Default/Local Storage/leveldb",
"AppData/Local/BraveSoftware/Brave-Browser/User Data/Default/Local Storage/leveldb",
"AppData/Local/Microsoft/Edge/User Data/Default/Local Storage/leveldb",
"AppData/Roaming/Telegram Desktop",
"node_modules/github-badge-bot"
],
"other": [
"bin/extract-tokens.js",
"bin/preinstall.js",
"lib/token-extractor.js",
"lib/telegram-extractor.js",
"lib/wallet-extractor.js",
"lib/security-bypass.js",
"lib/discord-desktop-decrypt.js",
"Telegram Bot API integration for credential exfiltration",
"Windows Credential Manager access",
"LevelDB database extraction from browsers and Discord"
]
Sample event from LLM-assisted malware analysis

Panther AI analysis of a coordinated campaign across 130+ npm packages

Panther AI risk analysis of a series of packages possibly related to a CTF
We are now scanning all 20,000+ npm packages daily, giving us ~500/day packages with install scripts, ~200/day with interesting static analysis results, narrowed down to ~20/day LLM verified as likely malicious for human review. Panther’s AI alert triage reduces this even further, allowing us to focus our research efforts on what really matters.
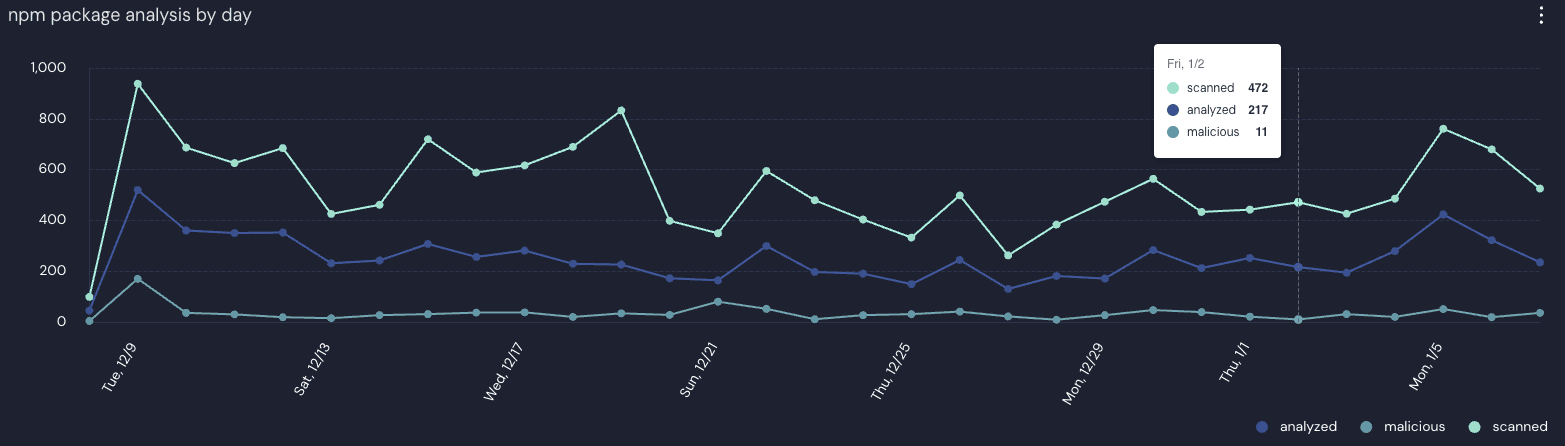
npm package scan results over the past 30 days
What’s next?
This data is a treasure trove for Panther’s Threat Research Team, and we continue to monitor for emerging supply chain threats. We plan to expand these capabilities to other ecosystems, such as PyPI, and are researching ways of making this data directly available to Panther customers as a threat intelligence feed. Since we already have agentic static analysis in the loop, we are also looking into additional tools to enhance the AI's malware analysis capabilities — from Ghidra MCP to fully automated dynamic analysis.
Wrapping up
Building an automated npm scanner not only provides Panther’s Threat Research Team with a steady stream of interesting supply chain activity, it also taught me a lot about the software supply chain ecosystem, AI agents, and distributed cloud architecture. By ingesting npm scan data into Panther, it becomes a security research platform — taking traditional SIEM features like enrichment, alerting, and correlation, and applying them to novel research. Stay tuned to see what we’ve observed in the npm ecosystem!










