Method to the Madness: Developing a Detection Engineering Methodology
Ken
Westin
Jan 24, 2023
Writing detections is both an art and a science Ai sometimes a black art and weird science. When shopping for a SIEM, some organizations may look at the number of detections available out of the box; however, many times, these detections generate irrelevant alerts with a high volume of false positives. I have been involved in professional service engagements where the engineer first disables all out-of-the-box detections due to the flood of false positives they generate. Then detections are slowly enabled and tuned to fit the customers' environment.
One challenge that many security teams face is how to go about creating new detections that will improve their capabilities and security posture. SIEMs require care and feeding, from managing the IT infrastructure, continuous integration of new data sources, and creating and tuning new detections. Enabling and tuning the initial round of detections is just the beginning of your organization's detection journey. When authoring new detections, it is essential to develop a methodology that starts with threat modeling, as well as input from security incidents, threat intelligence, threat hunting, and red/purple team activities.
Threat Modeling
Although threat modeling is an essential topic on its own, it is a beneficial tool to get started in developing hypotheses for detection use cases. Adam Shostack, who literally wrote the book on Threat Modeling, has proposed that most modern threat modeling approaches follow a simple Four Question Framework which I have modified slightly:
What are we looking to protect?
What can go wrong?
What are we going to do?
Did we do a good job?
1. What are we looking to protect?
It should be no surprise that hardware and software asset inventory are the two first and most foundational of the CIS Top 18 Security Controls. Although it may seem obvious to some what you are trying to secure, the devil is often in the details. We need to know what we are trying to protect before we can start writing detections. Today this has become a more significant challenge with the increased push to the cloud, where we are dealing with traditional hardware and software and ephemeral environments that evolve at an increasingly rapid pace.
Developing Data Flow Diagrams are another tool that is critically important to understand how assets and people interact within a system/network. To get started, the diagrams do not need to be overly complex and can help visualize trust boundaries, potential security gaps, and identification of data sources. Many different modeling languages can be used. There are often organizational assets that can be used as building blocks, such as network diagrams and other support to help get started.
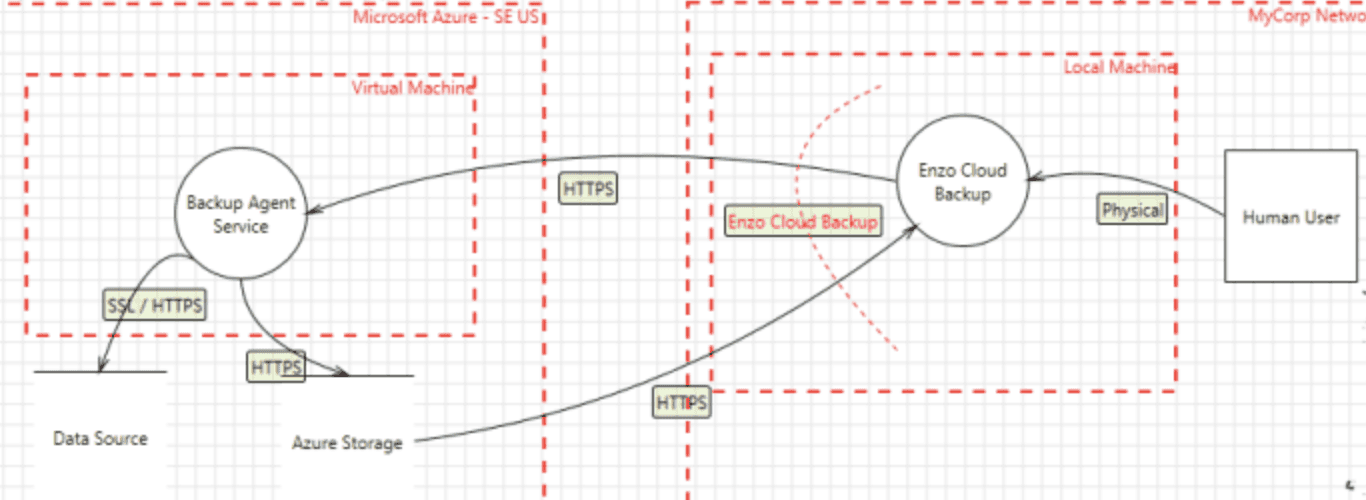
2. What can go wrong?
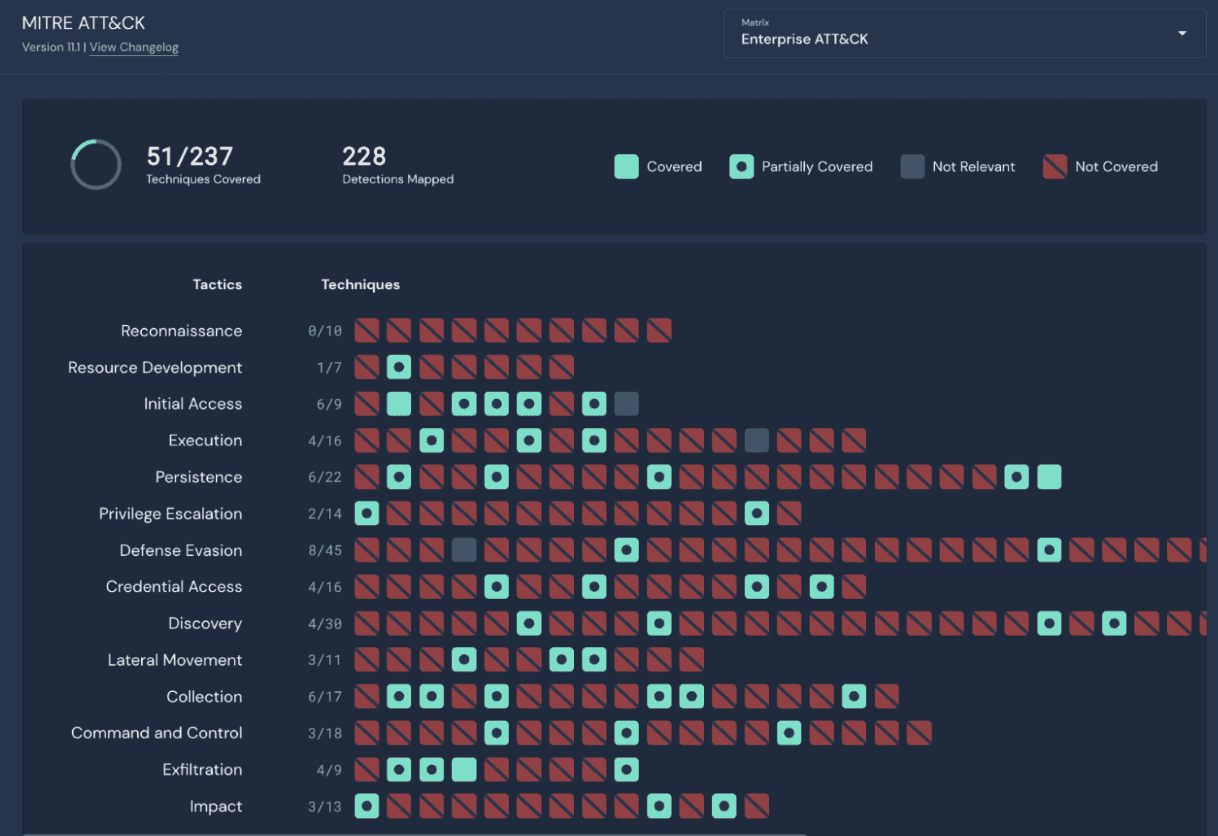
The next question is to identify what could go wrong; this process can be creative, particularly if you have individuals on the team well-versed in offensive security techniques. However, you don't need to be a master hacker to find what could go wrong. Using Kill Chains to conceptualize stages of an attack can help develop a layered approach to writing detections. Robust frameworks such as MITRE ATT&ACK provide detailed tactics and techniques which is yet another great way to identify areas to improve detection capabilities. Panther offers many easily customizable detections out-of-the-box, which are mapped to MITRE ATT&CK tactics and techniques, along with a helpful chart to show coverage.
Threat Intelligence
Threat intelligence can also be a great tool to develop detection hypotheses. Threat intelligence isn't just feeds of IoCs, but also includes shared incident reports, criminal complaints, vulnerability information, security news feeds, ISACs, and the larger cybersecurity community as a whole. The real power of using threat intelligence to help develop hypotheses for detections is leveraging the power of the security community Ai we are stronger together.
3. What are we going to do?
Now that we have a better understanding of what we are trying to protect and a general overview of our infrastructure, data sources, and potential threats, we can start creating detections. Many SIEMs on the market today will have a lot of out-of-the-box detections; however, it is often best to focus on quality over quantity; otherwise, you flood your security team with false positives or alerts that don't provide actionable context.
In addition to vendor-specific detection logic, which is often written in proprietary query languages, several open-source repositories are available to help get you started. Panther also provides an extensive collection of open-source detection rules written in Python. If you want to test these rules out quickly, I recommend signing up for a free Panther trial where you can try pre-built detections and write your own from scratch. Panther also offers several free detection-as-code webinars to help you get started.
4. Did we do a good job?
It is essential to point out that detection engineering is a continuous process. There is often a wealth of information available to defenders to build detection hypotheses: post-mortem of actual incidents, threat hunting, and red/purple team activities. The key findings we want to come out of these activities should be to evaluate what was missed that could have been detected. To capitalize on these activities requires that the organization have a Security Data Lake where logs are collected, which can be queried and replayed to reverse engineer new detection logic.
Incident Post-Mortem
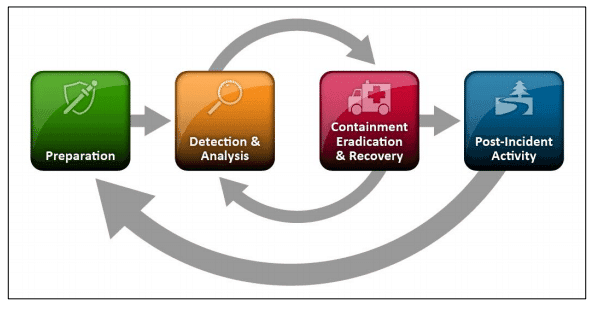
When an organization faces a security incident, it can be pretty chaotic depending on the severity; however, a silver lining is an organization's ability to conduct a post-mortem and "lessons learned" during an incident to improve detection and our overall security posture. The NIST Incident Response Lifecycle outlines this process and highlights the importance of a follow-up report on the incident; this can be a powerful tool for developing new detection hypotheses.
Threat Hunting
Threat Hunting is yet another great resource to develop hypotheses for new detections, as its core purpose is to identify threats that our boundary defenses and detections failed to recognize. When conducting threat hunting, it is essential to take notes, save queries and identify potential gaps in detection, whether it's a lack of detection logic or missing an entire data source to detect a particular threat.
Conclusion
When finding inspiration for writing new detections, there are often many more resources available than you may think, whether leveraging out-of-the-box, open-source, or bespoke rules that you write yourself based on threats you identify. The advantage of following a methodology is that the process is repeatable and continuous. In addition to developing a methodology for creating new detection logic, taking adetection-as-codeapproach further increases productivity by applying a Software Development Lifecycle approach to creating detection logic, enabling version control, collaboration, and unit testing. To learn more about leveraging the power of detection-as-code sign up for our hands-on workshops where we will guide you through the process.
Recommended Resources





Ready for less noise
and more control?
See Panther in action. Book a demo today.
