Identifying and Mitigating False Positive Alerts
Remy
Kullberg
Apr 11, 2024
TL;DR: To reduce false positive (FP) alerts, intentional decisions must be made regarding how to identify, track, and mitigate FPs. Successful efforts rely on repeatable processes ensuring consistency and scalability, while closing the feedback loop between detection creation and review.
Similar to cybersecurity incidents being a matter of "when" rather than "if," it's widely recognized that threat detection inevitably involves false positive alerts.
Incident responders understand false positives (FPs) as alerts that erroneously signal malicious activity. These alerts are typically viewed negatively because they clutter the threat detection environment and divert attention from genuine threats, thereby increasing overall risk.
The goal of this blog is to clarify the challenges and solutions associated with false positive alerts. You will gain insights into why FPs are prevalent, how to reduce FPs to an acceptable level, and why this is an urgent business priority. For long-term success, security teams must adopt a repeatable process that enforces consistency and scalability in threat detection.
Alert Fatigue: The Impact of False Positive Alerts
The primary impact of FPs is the wastage of incident responders' time. The 2023 Morning Consult and IBM report, "Global Security Operations Center Study," surveyed 1000 security operations center (SOC) members and found that an estimated one-third of their workday is spent on incidents that are not real threats, with FP and low-priority alerts comprising roughly 63% of daily alerts.
Time spent on false positives could otherwise be utilized to address real threats and enhance the systems detecting them. This includes proactive threat hunting for advanced threats, as well as automating workflows, improving visibility, and optimizing threat detection logic. Notably, 42% of 900 security practitioners surveyed in the Tines 2023 Voice of the SOC' report cited a high false positive rate as a top frustration.
However, it's the volume of alerts overall that creates challenging circumstances. Tasked with monitoring cloud-scale security data from highly distributed systems, incident responders are overwhelmed by a persistent influx of alerts, particularly FPs. This leads to alert fatigueAia state of burnout in which responders become desensitized to alerts, potentially missing or ignoring real incidents.
Researchers suspect that alert fatigue played a significant role in the 2013 Target breach that exposed 40 million credit and debit card accounts. Similarly, alert fatigue contributed to the more recent 2023 3XC supply chain attack, impacting a substantial number of customers who downloaded compromised software from 3XC's official site.
Other industry forces exacerbate alert fatigue. According to the Tines Voice of the SOC' report, 81% of responders reported increased workloads in 2023 amid an ongoing cybersecurity talent shortage that contributes to burnout and high employee turnover. Given this research, steps to reduce false positives are an urgent business need that will significantly decrease risk and have positive downstream effects on operations.
Why Good Threat Detection is Challenging
Here's the truth: it is indeed possible to create a detection that does not trigger false positive alerts. However, a detection that eliminates all noise focuses solely on detecting very high-fidelity Indicators of Compromise (IoCs), such as hash values of known malware executables or IP addresses and domain names of known Command & Control (CC) servers.
But how useful is such a detection? The use case would be narrow and fragile. IoCs change rapidly and have a short shelf life, while narrow use cases increase the risk of false negativesAiinstances where a detection fails to identify a threat variation it should catch. Command and control server domains change as soon as attackers realize they've been detected, rendering any detections based on such an IoC ineffective.
Instead, effective threat detection focuses on attacker artifacts, tools, and TTPs (tactics, techniques, and procedures). These reveal patterns of malicious behavior that are more challenging to detect but also more valuable because their usefulness does not expire as quickly. This hierarchy within threat detection is summarized in David J. Bianco's Pyramid of Pain.
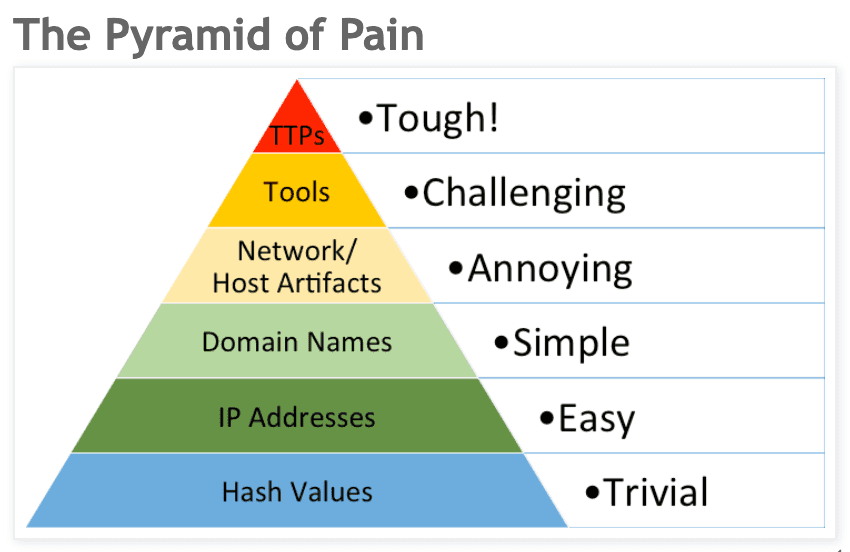
The top half of the pyramid is more difficult to detect and effectively identifies and stops attackers, whereas the bottom half is easier to detect but rarely stops or slows down attackers. The catch is that while basing detections on attacker behaviors and TTPs has the potential to be more effective, it also carries a greater risk of generating false positive alerts.
How to identify a false positive
Now, let's delve deeper into the definition. The National Institute of Standards and Technology (NIST) defines a false positive as "an alert that incorrectly indicates that a vulnerability is present."
Contrast this with its counterpart, a true positive (TP), which occurs when an alert correctly indicates that a vulnerability is present. Additionally, there are false negatives and true negatives, all of which are summarized in the following table:
Positive (+)Negative (-)TrueAlert is triggered; an attack is suspected. Detection logic is correctAithere's an attack!Alert is NOT triggered; systems appear normal. Detection logic is correctAisystems are normalFalseAlert is triggered; an attack is suspected. Detection logic is incorrectAisystems are normalAlert is NOT triggered; systems appear normal. Detection logic is incorrectAithere's an attack!
When detection logic does not work as expected, it's incorrect and will produce either a false positive or a false negative. These are both bad: false positives waste responder time, while false negatives effectively let an attack happen. Both scenarios need to be caught and remediated through detection tuning.
However, these definitions pose challenges in practical assessment.
From the perspective of an incident responder, it's more practical to identify false positives based on the outcome of an alert: what actions are necessary upon investigating the alert? If investigating an alert leads to no actionable response except closing the ticket, it's deemed a false positive.
Consider another category: true positive benign (TPB). This occurs when detection logic correctly identifies behavior indicative of a threat, but subsequent investigation reveals the behavior to be benign, caused by legitimate activity. Although the alert is a true positive, it is also benign, requiring no real remediation action. Is this type of alert effectively a false positive?
Ultimately, it's up to your security team to determine how to classify alerts.
Many teams opt not to differentiate between false positives, true positive benign alerts, or even duplicate alerts, as all result in no action beyond closing the ticket. The boundaries between these categories can become blurred, with the outcomeAiwasted timeAibeing the same regardless.
This emphasizes a key recommendation: define categories based on the actual work performed by incident respondersAispecifically, the actions taken or not taken in response to an alert.
Tracking False Positives
Once you've established effective methods for identifying false positives, the next step is to track them through categorization and labeling of alerts. This process mirrors the logic of developing a roadmap: first, determine your current position.
The metrics you choose to track will dictate the calculations you can perform. Aim to track and label alerts to identify which detections require tuning. Common metrics include:
Rate of false positives by detection, potentially breaking this down further to track indeterminate, duplicate, and true positive benign alerts.
Rate of true positives by detection, the inverse of your false positive rate.
Detections with the highest false positive and true positive rates.
Consider tracking additional metrics to gain insights into operational challenges and alert resolution:
Mean time to resolve an alert, identifying which alerts take the longest to address. Break this down by false positives and true positives, using this data to prioritize alert tuning. For instance, an alert generating frequent false positives with a quick resolution time may be less urgent to tune compared to an alert with infrequent false positives but a lengthy resolution process.
Number of false positives, low-priority true positives, and high-priority true positives resolved each day, providing an overview of daily workload distribution.
Mean time to complete individual runbook steps, pinpointing which steps are most time-consuming.
Mean time to detect true positive alerts, measuring the duration between the log timestamp and the alert timestamp.
Lastly, automate tracking and labeling wherever feasible, leveraging appropriate tools. For further discussion on metrics, refer to Alex Teixeira's Medium article on threat detection metrics (note: article access may be restricted by a paywall).
Setting a Target for False Positives
Armed with insights into the current state of false positives across your detections, the next step is to establish a target for improvement. Define an acceptable false positive rate per detection or focus on reducing overall time spent resolving false positives. For example, if your team dedicates 30% of the workday to false positives, aim to reduce this to 10% by prioritizing adjustments to the most problematic detections based on false positive rate and resolution time metrics.
You can also gauge and quantify detection efficacy by calculating the expected rate of true positive alerts relative to associated costs. For a comprehensive analysis, consult Rapid7's blog on calculating detection efficacy.
Mitigating false positives
Now let's explore methods to mitigate false positives by enhancing the quality of your detections.
1. Clearly define detection use cases
If you can't think of a specific action someone should take when they get an alert, then you haven't clearlyAior narrowlyAidefined the threat you're detecting, opening the door to false positives. Here's a checklist to help you clearly define your detection use cases:
Utilize threat intelligence. Quality detections rely on quality threat intelligence. Your organization's threat models and threat intelligence should direct detection development, starting with the most probable threats first.
Document. Record the use case, business goal support, and implementation details of each detection for auditing and change tracking. Ensure this documentation is accessible to a wide range of stakeholders.
Create runbooks. Create a runbook for every detection describing the specific actions to take in response to an alert.
Prioritize. Assign severity level to detections so that responders can prioritize their work, and track the prevalence of threats by severity. Report low or medium severity events periodically, not immediately.
Enrich. Where relevant, enrich alerts with context to improve alert fidelity and actionability. To add context to alerts, use custom lookup tables or threat intelligence feeds.
Use tagging. Tag each detection with metadata to track detection quality and the role of each detection within the broader threat detection framework. Metadata should cover aspects like threat coverage (MITRE ATT&CK tactic, technique, and sub-technique), log source and type, vendor, system or platform, analyst tier, business unit, and threat actor.
2. Maintain detections to prevent misconfigurations
Regular maintenance of detections is required to avoid misconfigurations that often generate false positives. Here's how to effectively maintain your detections:
Test detections. To confirm your detections function as intended, test them. Begin by testing new detections for valid, error-free logic. Then, assess detections against both historical and real-time data to gauge the frequency of false positives and tune your logic accordingly. Finally, detections should be continuously tested to ensure they remain effective as your system changes.
Set thresholds. Set accurate thresholds to avoid mislabeling routine behavior as malicious. Defining what is normal versus abnormal requires analysis, and may change over time.
Tune or disable. Remove any unnecessary detections. If a detection is generating false positives, adjust it. Conversely, if tuning a detection doesn't justify the effort, consider disabling it.
Manage exceptions wisely. Effective exception management reduces false positives by accounting for legitimate activity that otherwise would be considered malicious. For example, actions taken to deal with rare or unique situations, like copying and deleting a production database as part of a migration. Define detection exceptions globally and apply them across all detections for easier maintenance. Document each exception clearly for easy identification and review. Begin with specific exceptions and broaden as necessary. After creating exceptions verify that your detection continues to return true positives as expected.
Automate. Use a Security Orchestration, Automation, and Response (SOAR) tool to free up analyst time by automating remediation and tuning tasks. For instance, send "unusual login" notifications directly to users through your team communication platform for confirmation. Following a positive confirmation, automatically record the login's fingerprint as trusted, otherwise trigger an alert.
3. Invest in training and operations to support detection quality
Training and operations play an important role in mitigating false positives, as misconfigurations that lead to FPs can be a direct result of operational issues. Consider these aspects:
Refine operations. Effective threat detection that controls FPs requires regular feedback about alert quality from incident responders. Refining operations is about understanding team structures, roles, and needs in order to eliminate any silo (information, tools, processes) that degrades detection quality. For cross-functional teams, the antidote to silos is fostering communication, collaboration, and shared ownership over common goals.
Invest in training. Confirm whether your SIEM budget covers necessary training. If not, allocate training time and funding to equip analysts with the necessary skills to do their job. This could include vendor-specific training, general tech training (like AWS or Python), or working with your vendor's professional services (PS) team. It's vital for your team to learn and internalize the knowledge from the PS team the first time around, otherwise you'll be back to them next year.
Adopt modern tools. Understanding why a detection misfires is a core requirement to eliminating false positives. In this regard, modern tools provide practitioners with an undeniable edge: serverless, cloud-native SIEMs require zero infrastructure management and provide a security data lake with a year of hot data storage, which means data querying and investigation takes minutes, not days; and platforms that offer detection-as-code (DaC) are delivering the flexibility that analysts need to tailor threat detection to cover gaps and increase the fidelity of alerts.
4. Maintain data sources for enrichment and context
Data goes stale. Like detections, your SIEM and assets need maintenance in order to prevent false positive alerts and support faster incident response.
Maintain business assets. Data about employees provides crucial context for alerts that facilitates faster incident response, and generates false positives when it becomes outdated. This information includes mappings between employees and their hardware, role, department, accounts, and permissions. Keep business information current by either regularly uploading a comma separate values (CSV) file with asset information to your SIEM, or by setting up an automatic dump or stream updates from your Human Resource Information System (HRIS).
Stay current with vendor-managed content. Avoid acting on outdated risks and threats by updating your detections with new releases to vendor-managed detection content and configurations.
Maintain threat intelligence. Whether internal or third-party, threat intelligence is only as useful as it is up-to-date. Implement a regular review process for your threat intelligence sources to ensure they are current.
It's a (repeatable) process: The detection development lifecycle
A high-fidelity alert can miss variants and produce false negatives, whereas a low-fidelity alert generates too many false positives. Simply put, the aim of effective threat detection is to strike a balance.
But true success in creating quality threat detection is making the development process repeatableAia process that ensures consistency, inspires confidence in the threat detection program, and is scalable in response to evolving business requirements and risk.
Above all, a robust detection development process closes the feedback loop between creation and review, so that detections are regularly updated and retired as systems change, cutting down on false positives.
This is your sign to assess your organization's detection development process to determine if it supports your team's ability to maintain detection content at every stage in the lifecycle. Many cybersecurity practitioners and leaders have contributed to the public knowledge base, offering resources to guide you:
A compilation of detection engineering resources (frameworks, concepts, detection content), maintained by infosecB.
Snowflake's Detection Development Lifecycle and Threat Detection Maturity Framework, published by Haider Dost and contributors.
A blog series on the challenges in detection development by Anton Chuvakin, Amine Besson, and other collaborators.
Modern tools for modern threat detection
Does your SIEM meet your team's needs? Learn how to evaluate a threat detection platform and determine whether it is built to deliver efficiency, performance, and alert fidelity at scale.
Panther is the leading cloud-native SIEM offering the highly flexible detection-as-code backed by a serverless security data lake. Request a demo to try Panther today.
Recommended Resources





Ready for less noise
and more control?
See Panther in action. Book a demo today.
