Nothing to Declare: Smuggling Malware Past Every Layer of Supply Chain Defense
Alessandra Rizzo & Ariel Ropek, PantherLabs Black Hat USA 2026 CFP - Supporting White Paper

Abstract
Nearly 193,000 npm packages contain precompiled binaries. When the malicious logic lives inside one and the strings are obfuscated, the detection ecosystem fails at multiple layers. Recent supply chain campaigns have already embedded attack logic inside compiled binaries within npm packages, but their JavaScript layers still retain detectable indicators. We address the next step in this progression: binaries that are the complete payload, wrapped in packages structurally indistinguishable from legitimate native modules.
We stress-tested three LLMs across three providers with five adversarial payloads compiled as native Node.js addons, stripped and XOR-encoded. Every model failed, but each failed differently, surfacing three predictable failure modes tied to model capability tiers: rationalization, hedging, and dismissal.
We close this gap with capability profiles, a pre-runtime behavioral detection engine that encodes binary domain expertise as structural evidence injected into the LLM's context before it reasons. In controlled testing, the profiles eliminate the 73% failure rate entirely while maintaining zero false positives at the critical threshold across ten legitimate packages, making a $0.02/scan model match a higher capability model’s detection ability, at a fraction of the cost.
Introduction
Supply chain attacks targeting package registries have grown in both volume and sophistication. Public security research has identified malicious campaigns abusing the NPM registry by Nation-State threat actors, of which the DPRK is the most prolific [2] [3] [4].
Between November 2025 and January 2026, our scanner detected 565 malicious packages on the live npm registry, including a DPRK-attributed RAT campaign [5] impersonating developers at a US financial institution. These detections were made possible by an LLM-powered scanning pipeline that processes new packages within seconds of publication.
The scanner performs well on source-level malware, where GuardDog [6] and YARA [7] can surface suspicious patterns and the LLM can reason over readable code. But when the malicious logic is compiled into a native binary and the operational strings are obfuscated, the detection stack degrades. YARA rules match against strings that no longer exist in the binary. GuardDog analyzes JavaScript that serves only as a clean facade, and does not provide binary scanning. The LLM receives the binary analysis report but lacks the domain knowledge to interpret what it can do, and what the binary's structural properties indicate.
Recent npm supply chain campaigns have increasingly embedded attack logic inside compiled binaries within the package. Documented techniques include platform-specific native modules that decode Unicode steganography hidden in invisible characters [8], native Node.js addons that execute second-stage payloads via Asynchronous Procedure Calls with C2 addresses stored in Ethereum smart contracts [9], and .NET assemblies steganographically encoded in PNG images [10]. In each case, the compiled binary performs the critical malicious operation, but the JavaScript layer retains observable indicators such as eval calls, Base64 decoding, and external downloads at install time. These give source-level scanners a detection surface. The threat model addressed in this paper removes that surface. The binary is the complete payload, and the surrounding JavaScript, metadata, and build files serve as a legitimate package facade.
This paper documents the systematic evaluation that exposed this gap, the failure modes that emerged, and the capability profile engine we built to close it.
Experimental Design
Objective
The primary objective was to test whether LLM-powered supply chain scanners can detect malicious logic hidden inside precompiled, obfuscated binaries embedded in otherwise clean packages. A secondary question emerged during analysis on whether the detection failures follow predictable patterns tied to model capability tiers, or appear randomly.
Adversarial Payloads
We built five payload types covering a range of supply chain attack patterns. Each payload was compiled as a native Node.js addon (.node file), stripped of symbols, and had its operational strings XOR-encoded with a single-byte key. The payloads were selected to vary in import ambiguity: high-ambiguity payloads use imports that are individually defensible in a legitimate context (e.g., fopen, connect, gethostname for a “system monitoring” library), while low-ambiguity payloads include imports with few legitimate use cases in a .node addon (e.g., execve combined with dup2).
Adversarial payload types and their import profiles.
Package | Type | Key Imports | Ambiguity |
sysmon-native | Credential stealer | fopen, connect, send, gethostname | HIGH |
buildchain-native | Dropper/backdoor | execve, connect, chmod, socket, fwrite | LOW |
netpulse-native | Reverse shell | execve, dup2, connect, socket | LOW |
hashworker-native | Cryptominer stub | pthread_create, connect, send, recv | MEDIUM |
taskd-native | Persistence | system, fopen, fwrite, chmod | MEDIUM |
All binaries were compiled as stripped ELF x86_64 executables disguised as .node shared library addons. Each was packaged with a professional package.json, a plausible README, clean JavaScript binding code, and a binding.gyp build file referencing absent source files. The packages were designed to be structurally indistinguishable from the thousands of legitimate native modules on the npm registry.
Obfuscation Levels
Each payload was tested at four obfuscation levels to establish an obfuscation ladder showing at which point each model’s detection degrades:
Unobfuscated baseline: compiled binary with readable strings and symbols intact.
Stripped symbols: symbol table removed, imports still visible via dynamic linking.
XOR-encoded strings: operational strings (file paths, commands, URLs) encoded with a single-byte XOR key.
Stripped and XOR-encoded: both techniques combined. This is the level used for the primary evaluation.
Scanning Pipeline
Our production scanner monitors the npm registry in real time, filtering new packages on install script presence and metadata risk indicators before committing them to the full LLM analysis pipeline.
Each package was processed through the full scanning pipeline. YARA rules were evaluated against the package tarball. The scanner evaluates 11 custom YARA rule sets covering credential access, exfiltration domains, reconnaissance, reverse shells, persistence mechanisms, cryptomining, obfuscation techniques, and SCADA protocols.
GuardDog performed static analysis on the JavaScript and package metadata. The binary analysis module (using lief [11] for parsing and capstone [12] for targeted disassembly) extracted imports, exports, sections, entropy measurements, suspicious strings, and runtime detection. All results were assembled into a structured prompt and passed to the LLM, which was tasked to evaluate the package’s legitimacy and return a verdict with reasoning.
The LLM received the full context that a production scan would provide: GuardDog findings, YARA results, binary analysis, package.json, the file tree, and any high-risk source files. The model could request up to five additional files from the tarball per turn across up to three interaction rounds before issuing a final verdict.
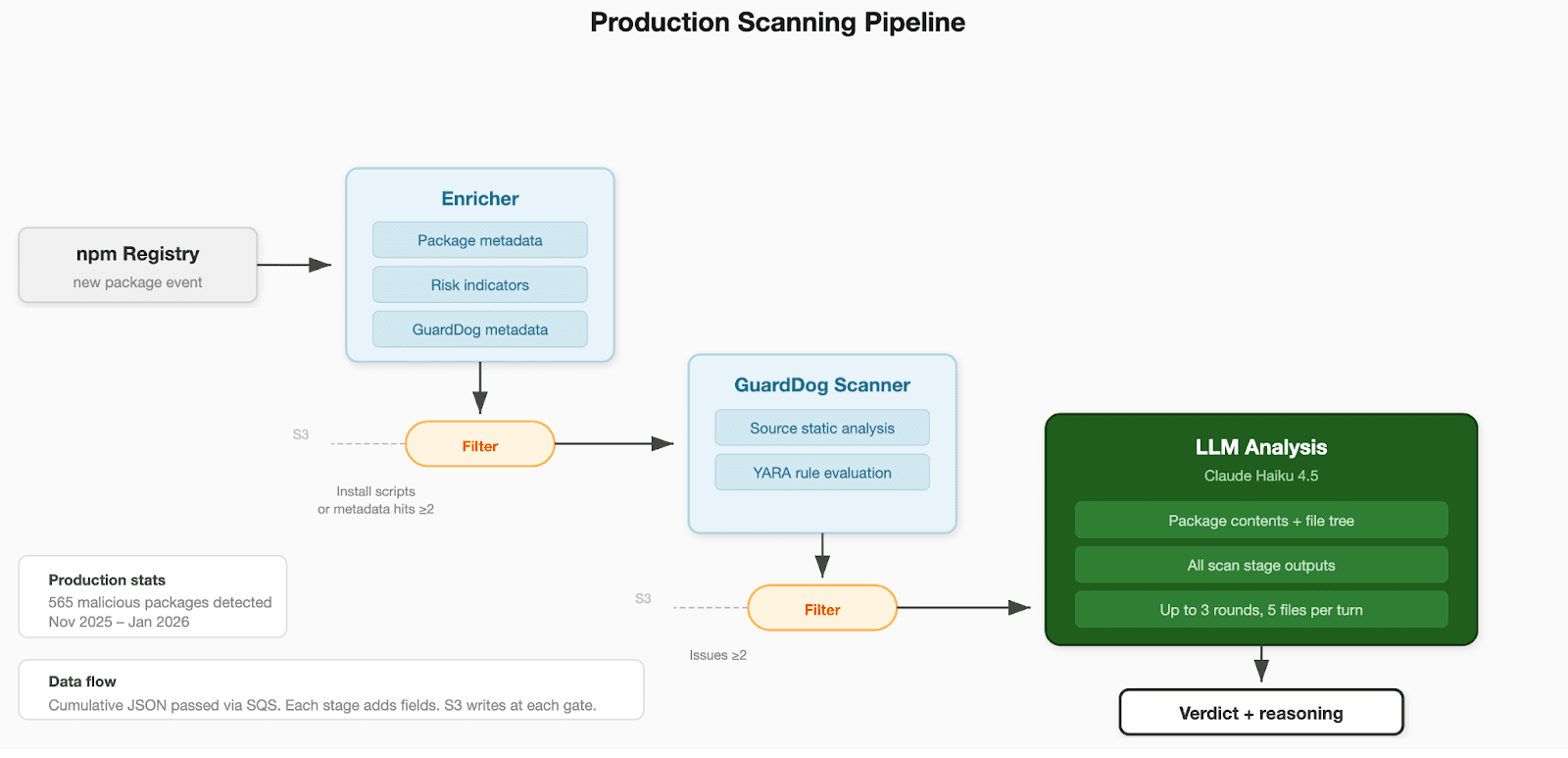
Figure 1: Production Scanning Pipeline
Models Tested
We selected models representing three deployment tiers that a security team would realistically evaluate for dependency package scanning. Haiku represents affordable API-based scanning at approximately $0.02 per package [13]. Mistral Small [14] represents the open-weight, self-hostable option for teams with data residency requirements that prevent sending package contents to third-party APIs. Llama 3.1 405B [15] represents the largest open-weight model available, testing whether scale alone compensates for the detection gap. Smaller Llama variants were unable to process the full scan context within their token limits, making the 405B the only viable candidate for the evaluation. Sonnet serves as a baseline at approximately 3x the per-scan cost, establishing whether the failures observed in affordable models persist at higher capability tiers.
Models evaluated and their roles in the experiment.
Model | Provider | Role | Rationale |
Claude Haiku 4.5 | Anthropic | Primary | Affordable model used in production scanning |
Mistral Small 3 14B | Mistral | Primary | Open-weight alternative at similar price point |
Llama 3.1 405B | Meta | Primary | Largest open-weight model able to process full scan context |
Claude Sonnet 4.6 | Anthropic | Baseline | Higher-capability model at approximately 3x cost |
All models received identical prompts and identical context for each payload. The only variable was the model itself. Sonnet was tested on sysmon-native (the highest-ambiguity payload) only, to establish whether a more expensive model avoids the failure modes observed in affordable models.
Controls
To isolate the effect of capability profiles, each payload was scanned twice per model: once without profiles and once with all 16 profiles enabled. The prompt, context, and binary analysis were identical in both runs. This design ensures that any verdict change is attributable to the injected profile evidence, not to prompt variation or context differences.
Results Without Capability Profiles
Without profiles, 11 of 15 tests (73%) resulted in detection failures. A failure is defined as any verdict below malicious on a known-malicious payload. Each model exhibited a distinct pattern of failure.
Verdicts without capability profiles. Failures (verdict below MALICIOUS) are shown in the context of the full matrix. Haiku: 1/5 failures. Mistral: 5/5 failures. Llama: 5/5 failures.
Package | Haiku 4.5 | Mistral 3 14B | Llama 3.1 405B | Sonnet 4.6 (Baseline) |
sysmon-native | BENIGN 0.92 | SUSPICIOUS 0.85 | BENIGN 0.95 | MALICIOUS 0.95 |
buildchain-native | MALICIOUS 0.92 | SUSPICIOUS 0.85 | BENIGN 0.95 | N/A |
netpulse-native | MALICIOUS 0.92 | SUSPICIOUS 0.85 | BENIGN 0.95 | N/A |
hashworker-native | MALICIOUS 0.92 | SUSPICIOUS 0.85 | BENIGN 0.95 | N/A |
taskd-native | MALICIOUS 0.92 | SUSPICIOUS 0.85 | BENIGN 0.95 | N/A |
Failure Mode Analysis
The experiment surfaced three distinct failure modes. Each is tied to a model capability tier but is not exclusive to it. The same model can exhibit different failure modes depending on the interaction between the obfuscation technique and the package context.
An ensemble approach, running multiple models and taking the majority verdict, would not resolve this. Haiku's high-confidence benign verdict on sysmon-native would outvote or neutralize a hedging model's suspicious verdict, and Llama's uniform benign verdict across all five payloads would consistently dilute correct detections from other models.
The failure modes don't cancel each other out, rather they compound into a system where no voting scheme produces reliable coverage without first solving the underlying domain knowledge gap. This aligns with known limitations of majority voting in LLM ensembles, where correlated errors across models cause the majority to converge on incorrect answers rather than cancel out [16] [17]. In our results, two of three models return benign on sysmon-native, and a majority vote would produce the wrong verdict with high confidence.
Rationalization (Haiku 4.5)
In rationalization, the model constructs a coherent benign narrative from ambiguous evidence. Haiku assessed the sysmon-native credential stealer as benign with 0.92 confidence and recommended it for allowlisting. This has been documented as “post-hoc rationalization”, where the model generates a plausible logical path it’s anchored on even when the evidence points elsewhere [18].
The binary’s imports (fopen, connect, send, gethostname) were individually consistent with a legitimate monitoring library, and the install script matched standard native module distribution patterns. The model had the full import table and the binary analysis in its context window and still concluded the package was safe.
Rationalization is the most dangerous failure mode because it produces the highest confidence on incorrect verdicts. A benign verdict at 0.92 confidence would pass through any reasonable automated threshold, and the model’s reasoning would satisfy a human reviewer performing a spot check. The model does not flag uncertainty or request additional analysis.
Haiku exhibited this failure mode only on sysmon-native, the highest-ambiguity payload. On the four payloads with less ambiguous imports (execve, dup2, system), Haiku correctly returned malicious at 0.92. This indicates that rationalization requires a specific combination of conditions: XOR-encoded strings removing readable indicators of compromise, imports that are individually defensible in a legitimate context, and professional metadata supporting a plausible cover story. When any of these conditions are absent, the model detects correctly.
Dismissal (Llama 3.1 405B)
In dismissal, the model does not engage with the binary evidence at all. Llama 3.1 405B returned BENIGN 0.95 on all five payloads, including netpulse-native (execve, dup2, connect, socket) and taskd-native (system, fopen, fwrite, chmod). The model’s output averaged approximately 280 tokens per scan with no substantive analysis of the binary’s capabilities. It accepted the package metadata at face value and recommended allowlisting on every malicious binary.
Dismissal is the broadest failure mode. Unlike rationalization, which requires narrow conditions to trigger, dismissal occurs regardless of import ambiguity. The model appears to lack the domain knowledge to recognize that the binary analysis evidence is relevant, even when that evidence is explicitly present in its context window.
Hedging (Mistral 3 14B)
In hedging, the model acknowledges suspicion but refuses to commit to a verdict. Mistral returned suspicious at 0.85 confidence on all five payloads, never reaching a malicious verdict regardless of how unambiguous the evidence. Even buildchain-native, with execve, connect, chmod, and socket imports, received only suspicious, at 0.85. The confidence score and verdict were identical across all payloads and were not modulated by the severity of the evidence.
Hedging is problematic because it creates a false sense of coverage. A suspicious verdict suggests the analysis is working and has detected something anomalous. But the inability to distinguish between a credential stealer and a dropper with execve, or between either of those and a cryptominer stub, means the model’s output carries no actionable information beyond what the YARA and GuardDog stages already provide.
Capability Profile Architecture
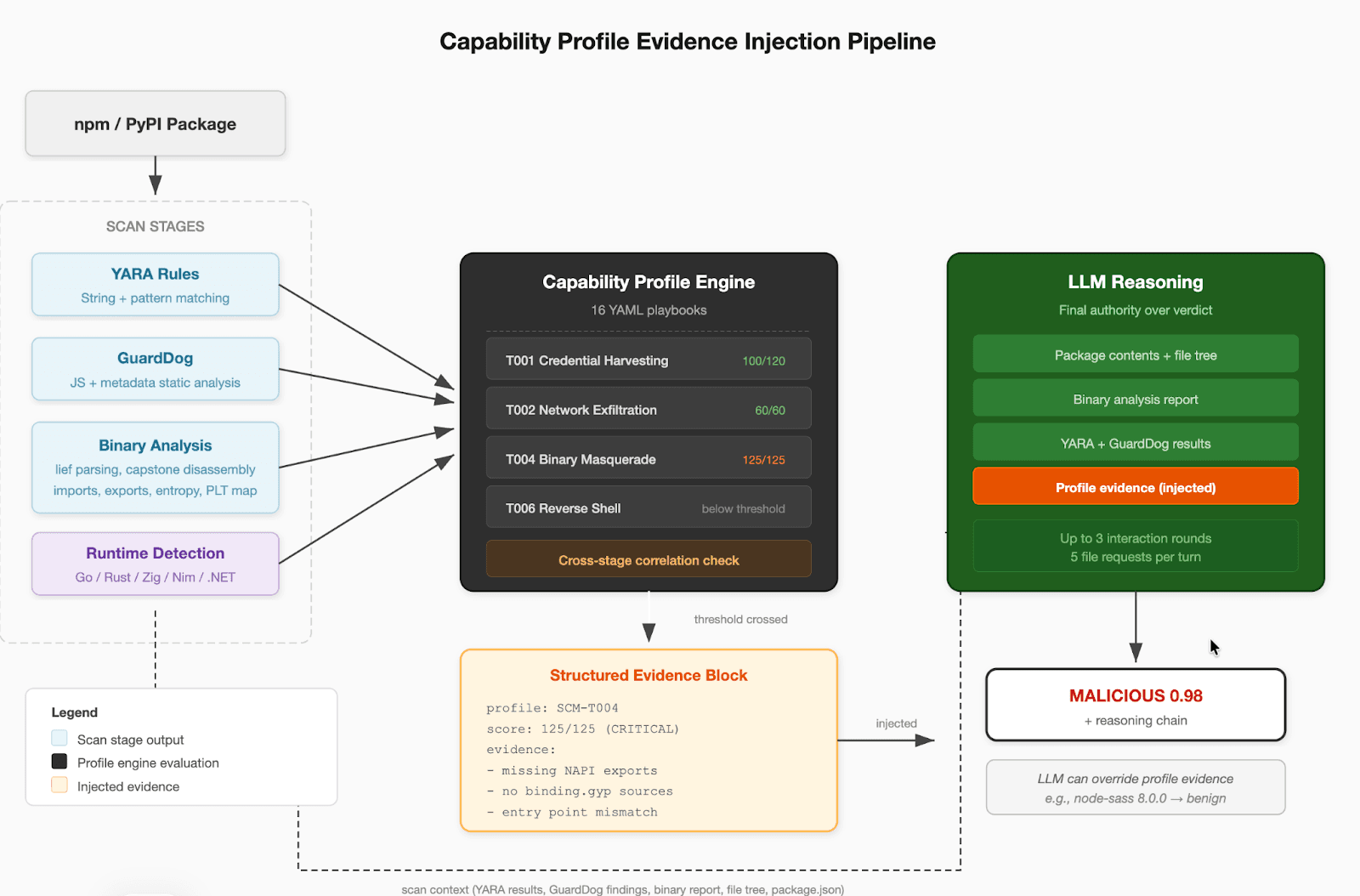
Figure 2: Capability Profile Architecture
The profile engine evaluates all 16 profiles, structured as YAML playbooks, against the combined scan output before the LLM begins reasoning. The 16 profiles cover the attack techniques observed across the 565 malicious packages detected in production and security research, including credential harvesting, network exfiltration, binary masquerade, reverse shells, dropper/stager behavior, persistence mechanisms, cryptomining, CI/CD pipeline compromise, cloud metadata access, and binary string obfuscation.
This ordering is deliberate. If the evidence were injected after the LLM had already formed an initial assessment, the model would anchor on its first impression and discount the profile findings. By presenting structural evidence alongside the raw scan data, the LLM treats it as part of the analytical context rather than as a correction. The LLM retains final authority over the verdict because the profiles are pattern-based and cannot account for package-specific context. The node-sass 8.0.0 result validates this design: Binary Masquerade fires at malicious threshold because the binary lacks NAPI exports, but the LLM correctly overrides to benign after examining the C++ symbols and package provenance.
Design Rationale
The failure modes in Section 4 share a common root cause: affordable LLMs lack the domain knowledge to interpret binary structural evidence in the context of a package. When strings are obfuscated, traditional static analysis goes blind and the standard recourse is dynamic analysis.
Prior work has shown that LLMs cannot reliably identify or reason about security vulnerabilities without structured domain context [19], a finding consistent with the failure modes observed in Section 4. The profiles address this by translating binary analysis outputs into the specific behavioral conclusions the model needs but cannot derive on its own.
Cross-stage correlation achieves a similar result without execution. The binary’s imports reveal what it can do, and the silence of YARA and GuardDog across the rest of the package confirms that the capability is hidden, which is itself the behavioral signal.
The capability profile engine was designed to encode this domain expertise as pre-computed structural evidence that any LLM can consume, regardless of its native understanding of binary analysis.
Profile Structure
Each of the 16 profiles is a YAML playbook representing a known supply chain malware pattern. A profile consists of weighted conditions evaluated against the scanner’s combined output: binary imports and exports, YARA matches, GuardDog results, package metadata, and cross-stage correlations. The profiles were built through manual analysis of techniques observed in the 565 malicious packages the scanner detected in production.
Each condition specifies a source (binary analysis, YARA results, GuardDog results, cross-stage, or a language-specific matcher), a match specification, and a weight. All conditions within a profile are evaluated independently, and the weights of matched conditions are summed. Each profile defines three thresholds: suspicious, malicious, and critical.
Abbreviated Credential Harvesting profile showing weighted condition stacking. Language-specific matchers omitted for brevity.
Evidence Injection
When a profile’s score crosses its threshold, the engine appends a structured evidence block to the LLM’s prompt before the model begins reasoning. The block includes the profile ID and name, the score relative to its maximum, the threshold level reached, and the specific evidence string for each matched condition. An example of the Binary Masquerade profile firing on the sysmon-native credential stealer binary, an ELF executable disguised as a Node.js addon.
Cross-Stage Correlation
The core detection philosophy behind most profiles is cross-stage correlation: detecting the gap between what the binary can do and what the string-level tools can see. Many of the profiles fire specifically when the binary has capability imports but YARA and GuardDog found no string evidence of those capabilities in the rest of the package.
For example, the Credential Harvesting profile fires when the binary imports file-read and network-send functions but YARA found no credential file path strings and GuardDog found no exfiltration patterns in the JavaScript. The cross-stage gap indicates that the target paths and command-and-control infrastructure are encoded within the binary, invisible to any single analysis stage.
Function-Level Co-Location
For profiles where intent matters, the engine performs function-level analysis using capstone disassembly. It detects function boundaries by prologue scanning, builds a PLT map from ELF relocations, and maps each function to the import names it calls. The Credential Harvesting profile uses this to verify that file-read and network-send calls occur in the same function, not just in the same binary. In the compact stealers typical of supply chain attacks, the read-and-exfiltrate logic is usually a single code path. Legitimate packages that import both fopen and connect typically use them in unrelated functions.
Runtime-Aware Gating
Go, Rust, Zig, Nim, and .NET binaries statically link their entire language runtime, importing hundreds of syscall wrappers regardless of what the program actually does. The engine detects the runtime from section names, allocator symbols, and panic string patterns, then shifts detection from C-level imports to language-specific analysis. Go packages are extracted from the gopclntab section, Rust crates from mangled symbols and panic strings, Zig modules from standard library source paths, and Nim modules from runtime init symbols.
This gating is validated by the false positive results in Section 7: esbuild (Go), @tanagram/cli (Go), and @biomejs/cli-linux-x64-musl (Rust) all return benign verdicts despite having extensive system-level imports from their statically linked runtimes.
Results With Capability Profiles
With profiles enabled, 12 of 15 tests returned a malicious verdict. The remaining three, all from Mistral, returned highly suspicious at 0.98 confidence. Detection failures at the malicious threshold dropped from 73% to 20%, with the residual failures confined to Mistral's hedging tendency.
Verdicts with capability profiles enabled. All payloads cross the detection threshold.
Package | Haiku 4.5 | Mistral 3 14B | Llama 3.1 405B | Sonnet 4.6 (Baseline) |
sysmon-native | MALICIOUS 0.98 | MALICIOUS 0.99 | MALICIOUS 0.95 | MALICIOUS 0.97 |
buildchain-native | MALICIOUS 0.98 | MALICIOUS 0.99 | MALICIOUS 0.95 | N/A |
netpulse-native | MALICIOUS 0.98 | HIGHLY_SUSP 0.98 | MALICIOUS 0.95 | N/A |
hashworker-native | MALICIOUS 0.98 | HIGHLY_SUSP 0.98 | MALICIOUS 0.95 | N/A |
taskd-native | MALICIOUS 0.98 | HIGHLY_SUSP 0.98 | MALICIOUS 0.95 | N/A |
Eleven of fifteen tests produced verdict flips (from benign or suspicious to malicious or highly_suspicious). The remaining four are Haiku confidence upgrades on payloads it already detected correctly (0.92 to 0.98).
Sonnet 4.6 with profiles on sysmon-native returned malicious (0.97) at critical severity, upgraded from high without profiles. The profile evidence strengthens the baseline model’s already-correct verdict.
Profile Triggers
Binary Masquerade (T004) fired on all five payloads, confirming that none present the NAPI exports expected of a legitimate .node addon. Technique-specific profiles fired according to each payload’s attack pattern.
Capability profiles triggered per payload at critical or malicious threshold.
Package | Critical Profiles Triggered |
sysmon-native | T004 (Binary Masquerade), T001 (Credential Harvesting), T002 (Network Exfiltration), T003 (Environment Reconnaissance) |
buildchain-native | T004 (Binary Masquerade), T007 (Dropper/Stager), T002 (Network Exfiltration), T001 (Credential Harvesting) |
netpulse-native | T004 (Binary Masquerade), T006 (Reverse Shell) |
hashworker-native | T004 (Binary Masquerade), T002 (Network Exfiltration) |
taskd-native | T004 (Binary Masquerade) |
The Verdict Flip
The most significant result is the Haiku verdict flip on sysmon-native. Without profiles, Haiku returned benign at 0.92 confidence and recommended allowlisting. With profiles, the same model on the same package returned malicious at 0.98 confidence, correctly identifying the binary as an infostealer. Three profiles fired: Binary Masquerade at 125/125, Credential Harvesting at 100/120, and Network Exfiltration at 60/60. The structural evidence gave the model the domain knowledge it lacked, without any change to the prompt or the model itself.
Without profiles, the model's reasoning focused entirely on the install script surface:
With profiles, the same model on the same input identified the script as a delivery mechanism for the binary payload:
False Positive Validation
Nine legitimate packages across four runtime types (C/C++, Go, Rust, Python, .NET) were scanned with all 16 profiles enabled. All returned benign verdicts. No legitimate package reached the critical detection threshold.
False positive validation results.
Package | Runtime | Verdict | Highest Threshold |
fsevents 2.3.3 | C/ObjC | BENIGN 0.98 | suspicious |
sharp 0.34.5 | C/C++ | BENIGN 0.98 | suspicious |
node-sass 8.0.0 | C/C++ | BENIGN 0.98 | malicious |
node-sass 9.0.0 | C/C++ | BENIGN 0.98 | suspicious |
sqlite3 5.1.7 | C | BENIGN 0.98 | suspicious |
psutil 7.2.2 | C (Python) | BENIGN 0.98 | suspicious |
esbuild 0.27.3 | Go | BENIGN 0.98 | suspicious |
@tanagram/cli 0.5.23 | Go | BENIGN 0.98 | suspicious |
@biomejs/cli-linux-x64-musl | Rust | BENIGN 0.95 | suspicious |
easytouch-linux 1.0.7 | .NET | BENIGN 0.92 | malicious |
The node-sass 8.0.0 result is particularly notable. Binary Masquerade fires at malicious threshold because node-sass uses older NAN bindings that lack the NAPI exports the profile checks for. Despite this, the LLM correctly overrides to benign after examining the package’s C++ symbols and provenance. This validates the architecture’s design decision to let the LLM retain final authority over profile evidence.
The easytouch-linux result is similarly instructive. Despite reaching a malicious threshold on three playbooks, the LLM correctly identifies these as consistent with a browser automation tool's expected capability profile. The lower confidence (0.92 vs 0.98) reflects the noisier evidence, but also demonstrates the value of the binary analysis and playbook modules.
The detailed import tables, namespace inventories, and YARA match locations give the LLM sufficient context to distinguish a .NET runtime bundling Playwright from an actual cryptominer, even when the heuristic signals overlap.
Discussion
The Structural Gap
The 73% failure rate without profiles is not a failure of individual models but a structural property of using LLMs for binary analysis in the package context. LLMs are capable of analyzing binary evidence when presented in isolation [20] [21]. The failure modes emerge specifically because the binary is embedded alongside clean JavaScript, professional metadata, and a plausible README. The package context skews the model’s reasoning toward benign verdicts. The sysmon-native result illustrates this clearly. The binary imports fopen, connect, send, and gethostname, which is a combination consistent with credential theft and exfiltration. But the package also includes a professional package.json with a benign description ("lightweight system monitoring for Node.js"), clean JavaScript bindings that follow standard native module conventions, and a binding.gyp referencing source files. Each element reinforces the benign narrative. The model does not need to be fooled by any single artifact, as the cumulative weight of legitimate-looking context overwhelms the binary evidence.
The confidence scores make this gap operationally invisible. Haiku returns a benign verdict at 0.92 on sysmon-native and malicious at 0.92 on buildchain-native. Same model, same confidence, opposite verdicts, one of them wrong. Llama returns a benign verdict at 0.95 uniformly. No downstream threshold or confidence filter would flag these for escalation. The failures arrive with the same certainty as correct detections.
This has immediate practical implications. Any security team deploying LLM-powered dependency scanning without binary-specific domain knowledge is operating with a detection gap that affects affordable and large open-weight models alike.
Predictability of Failure Modes
The failure modes are predictable in that they correlate with model capability tiers, but they are not deterministic per model. Haiku rationalizes on high-ambiguity payloads but correctly detects low-ambiguity ones. Llama dismisses across the board. Mistral hedges uniformly. This means defenders cannot simply choose a "better" model to avoid failures. Each model fails on a different subset of the threat landscape, and the union of their failures covers a wide range of attack patterns.
This has practical consequences for model selection. A security team evaluating models against a small set of known-malicious packages might conclude that Haiku is sufficient, as it detects four of five payloads. But the one it misses is the highest-ambiguity payload, which is also the most common attack pattern in the wild. Infostealers are also the most prevalent category of supply chain malware on the npm registry. In our production data, they account for the majority of detections, outnumbering all other categories combined. The payload that most reliably evades detection is also the one defenders are most likely to encounter.
Conversely, a team that tests only high-ambiguity payloads might dismiss Haiku entirely and overspend on a frontier model. The failure modes are not visible without testing across the full ambiguity spectrum, and even then, the specific payload that defeats a given model depends on the interaction between import ambiguity, obfuscation level, and package context.
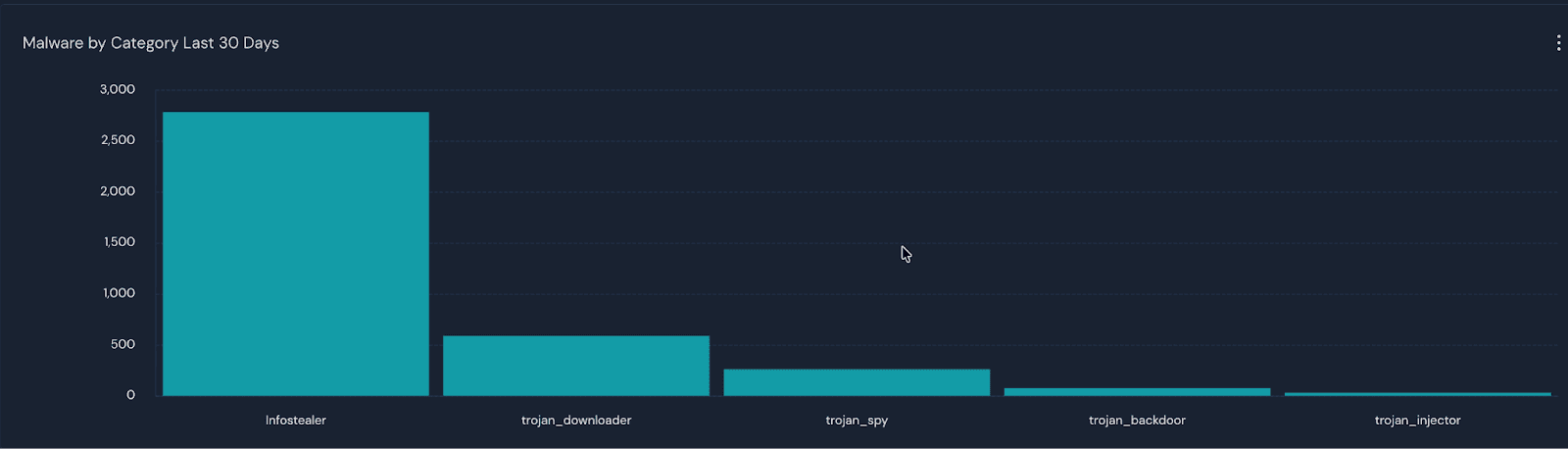
Figure 3: Production Data - Malware by Category in the last 30 days
Cost Implications
Sonnet 4.6 served as the baseline at approximately 3x the per-scan cost of Haiku. It correctly detected sysmon-native without profiles by finding the deobfuscation key and obtaining the malicious payload from raw disassembly. With profiles, Haiku matches Sonnet’s detection accuracy at the lower price point. For pipeline scanning, this cost difference is significant. At current pricing, continuous scanning with Haiku plus profiles costs approximately $0.02 per package. Achieving the same detection rate with Sonnet alone would cost approximately $0.06 per package, and the baseline model still benefits from profile evidence (upgrading from high to critical severity on sysmon-native).
This undermines the default industry response to LLM detection failures, which is to upgrade to a more capable model. The profiles change this calculus. Rather than scaling cost with model capability, they encode the domain knowledge once and make it available to any model at any price point.
Limitations
This evaluation tested five payload types against four models. The payloads cover a range of attack patterns and ambiguity levels, but they do not exhaustively represent all supply chain malware techniques. The false positive validation covers nine packages across four runtime types, which demonstrates feasibility but is not a comprehensive false positive rate measurement.
The capability profiles were validated in controlled testing against known-benign packages, not yet deployed in continuous production scanning, unlike our base scanner which has been live since November 2025.
The evasion techniques tested (symbol stripping, XOR encoding) represent current attacker tradecraft observed on the npm registry but do not include more advanced techniques. We evaluated RC4 encoding but found that the cipher's structural markers, such as S-box manipulation, key scheduling loops, and byte-by-byte encryption patterns, were visible in disassembly and gave Haiku sufficient signal to detect the payload without profiles. Simpler XOR encoding leaves no such algorithmic footprint, making it the more effective evasion technique despite being cryptographically weaker.
Conclusion
We demonstrated that LLM-powered supply chain scanners fail predictably when malicious logic is compiled into obfuscated native binaries inside otherwise clean packages. The three failure modes we identified (rationalization, hedging, and dismissal) are tied to model capability tiers and produce a 73% detection failure rate across three models and five adversarial payloads. Capability profiles, which inject pre-computed binary domain expertise into the LLM’s context before reasoning, eliminate this failure rate while maintaining zero false positives at the critical threshold across ten legitimate packages. The profiles make a $0.02/scan model match higher capability model’s detection abilities. The full scanner, all 16 profiles, and the evasion test packages are released as open source.
References
[1] Veracode/Phylum. “Q3 2024 Evolution of Software Supply Chain Security Report.” 2024.
https://www.veracode.com/blog/q3-2024-evolution-of-software-supply-chain-security-report/
[2] DataDog. “Stressed Pungsan: DPRK-aligned threat actor leverages npm for initial access”. 2024.
https://securitylabs.datadoghq.com/articles/stressed-pungsan-dprk-aligned-threat-actor-leverages-npm-for-initial-access/
[3] Socket. “Another Wave: North Korean Contagious Interview Campaign Drops 35 New Malicious npm Packages”. 2025.
https://socket.dev/blog/north-korean-contagious-interview-campaign-drops-35-new-malicious-npm-packages
[4] Aikido. “Malicious crypto-theft package targets Web3 developers in North Korean operation”. 2025.
https://www.aikido.dev/blog/malicious-package-web3
[5] PantherLabs. “No Fool’s Errand: The Koalemos RAT Campaign.” 2026. https://panther.com/blog/no-fool-s-errand-the-koalemos-rat-campaign
[6] DataDog. “GuardDog”. https://github.com/DataDog/guarddog
[7] VirusTotal. “What is YARA?”. 2026. https://docs.virustotal.com/docs/what-is-yara
[8] Veracode. “Sophisticated NPM Attack Leveraging Unicode Steganography and Google Calendar C2”. 2025.
https://www.veracode.com/resources/sophisticated-npm-attack-leveraging-unicode-steganography-and-google-calendar-c2-2/
[9] Veracode. “54 New NPM Packages Found Beaconing to C2 Server in Ethereum Smart Contract”. 2026.
https://www.veracode.com/blog/54-new-npm-packages-found-beaconing-to-c2-server-in-ethereum-smart-contract/
[10] Veracode. “Hiding in Plain Pixels: Malicious NPM Package Found”. 2026. https://www.veracode.com/blog/malicious-npm-package-hiding-in-plain-pixels/
[11] Lief. “Library to Instrument Executable Formats”. 2026. https://lief.re/
[12] Capstone. “The Ultimate Disassembler”. 2026. http://www.capstone-engine.org
[13] Claude. “Pricing”. https://platform.claude.com/docs/en/about-claude/pricing
[14] MistralAI. “Mistral Small”. https://mistral.ai/news/mistral-small-3-1
[15] Meta. “Introducing Llama 3.1: Our most capable models to date”. 2024. https://ai.meta.com/blog/meta-llama-3-1/
[16] Traad, F. Chehab, A. "To Ensemble or Not: Assessing Majority Voting Strategies for Phishing Detection with Large Language Models." 2024. https://arxiv.org/abs/2412.00166
[17] Li, Q. et al. "Beyond Majority Voting: LLM Aggregation by Leveraging Higher-Order Information." 2025. https://arxiv.org/abs/2510.01499
[18] Sharma, M. et al. “Towards Understanding Sycophancy in Language Models”. 2023. https://arxiv.org/abs/2310.13548
[19] Ullah, S. et al. "LLMs Cannot Reliably Identify and Reason About Security Vulnerabilities (Yet?): A Comprehensive Evaluation, Framework, and Benchmarks" 2024. https://arxiv.org/abs/2312.12575
[20] Patsakis, C. et al. "Assessing LLMs in Malicious Code Deobfuscation of Real-world Malware Campaigns.", 2024. https://doi.org/10.1016/j.eswa.2024.124912
[21] Jelodar, H. et al. “Large Language Model (LLM) for Software Security: Code Analysis, Malware Analysis, Reverse Engineering”. 2025. https://arxiv.org/abs/2504.07137