Osquery Log Analysis Guide
Jack
Naglieri
Aug 21, 2020
Onboard and analyze Osquery logs with Panther
Overview
Osquery is a powerful, host-based application that exposes the operating system as a set of SQLite tables. Security teams use osquery to track activity in their fleet such as user logins, installed programs, running processes, network connections, or system log collection.
In this tutorial, we will walk through how to configure osquery with Panther to create an end-to-end security alerting pipeline to send logs for analysis and then notifying your team on a specific activity. Panther also comes with pre-installed rules based on default query packs, which provides value for most osquery deployments.
For the purpose of this tutorial, we will assume an osquery installation on Ubuntu 18.04. This tutorial was last updated in February 2021.
Installation
To install osquery, follow the instructions here. Osquery can be installed on Mac, Linux, or Windows.
How It Works
Osquery periodically reports data by querying specific tables and sending results in JSON format to the configured logger_plugin(s), which can be the filesystem, a TLS endpoint, or AWS. The osquery.conf controls these settings, including other daemon (osqueryd) behaviors.
For example, the following query output can display all currently logged in
To schedule this query, we add it into the schedule in our osquery.conf:
When this query runs (every 3600 seconds), it will report results in a JSON log:
columnsare the results of the query we see abovenameis the descriptor for the scheduled queryactionindicates if this result is being added or removedhostIdentifieris the hostname which reported the log
When Panther receives the log, it will be parsed, extracted, and normalized based on fields such as IPs/domains to enable quick searches in the data warehouse and flexibility in rules. For the complete list of all fields parsed by Panther, check out the Osquery.Differential reference.
Configuration
Lets assume that we are sending osquery data from an Ubuntu machine in an AWS VPC.
To send to Panther, we will use the aws_firehose logger plugin. To provide the correct credentials, we will also use an IAM role and a Firehose Delivery Stream which will end up in an S3 bucket. The template here can be used to create the necessary infrastructure to enable this flow.
The /var/osquery/osquery.conf example below can be used to get started:
This configuration: Loads sample packs to provide a great baseline across many tables Adds decorations to all logs, which provides additional helpful context Assumes an IAM role, and sends to a Firehose delivery stream periodically
This pattern is easily scalable across a fleet of thousands of AWS VMs and can be customized to meet your needs.
To add your own queries, either write your own pack or simply add new queries to the schedule in the configuration above.
Sending to Panther
Follow this procedure to send Osquery data to Panther.
Daemon Status
Once your desired osquery configuration is in place, make sure to restart the osquery daemon. Also ensure that it is running with no errors. On Ubuntu, this looks like:
In the CloudWatch dashboard, you would begin to see metrics for the created DeliveryStream for IncomingRecords:
Onboard Data
Now with data flowing, lets onboard the S3 bucket containing osquery data into Panther.
From Log Analysis > Sources, click Add Source:
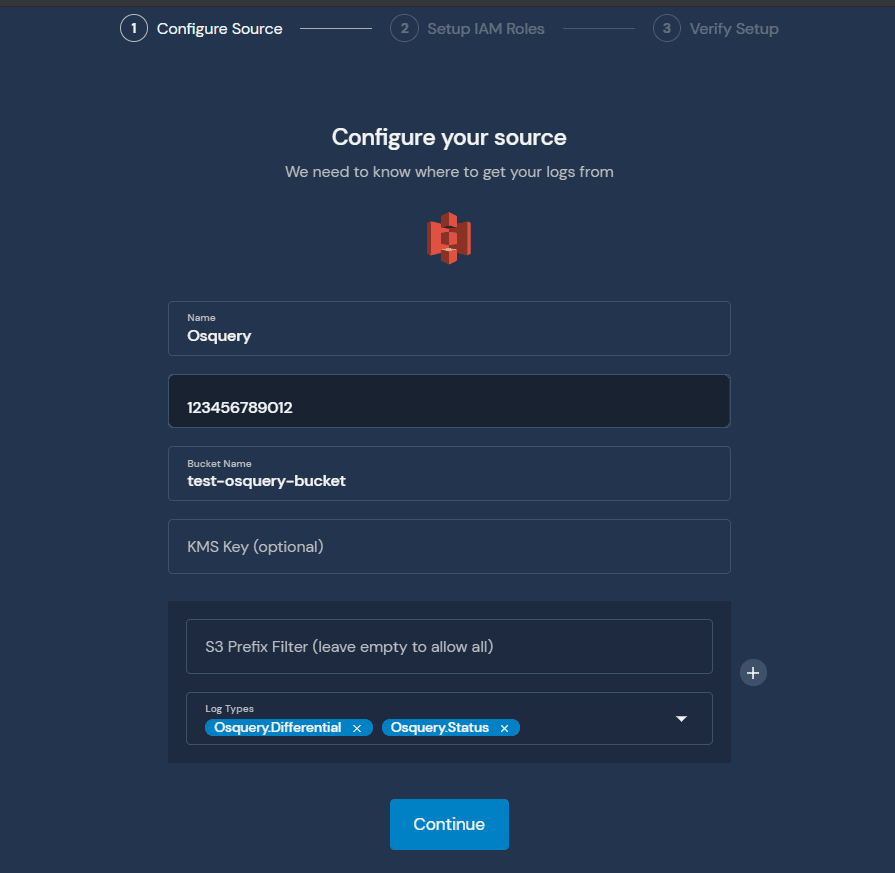
Note the Log Types in the screenshot above. If you plan to send Osquery logs either in Batch or Snapshot mode, make sure to add the log types in the initial screen.
Follow the instructions to create the IAM role to allow Panther to pull the data.
Then, save the source, and enable the notifications to onboard osquery data.
Validate
If everything is working, you should now see data in the panther_logs.osquery_differential table in Athena:
It may take up 15 minutes before data is searchable in Athena.
Analyzing Osquery Logs
Before writing any rules against osquery data, make sure to configure your alert destinations. This will provide a quick feedback loop on the rules written.
Log Types
Panther supports four types of osquery log schemas:
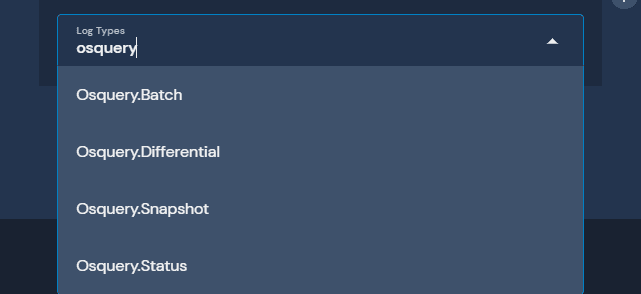
For most installations, Differential and Status will be the main two formats used unless specifically set in the configuration. Check out the osquery docs to learn more.
Writing Rules
Panther ships by default with several built-in example osquery rules that can also be used as a guide while writing your own.
There are two methods of analyzing osquery logs: alerting on any query results or analyzing the output of a query.
Alert on any query results
Generally, this method is used when a very specific query is written, for example:
Note: This query is taken from the
MacOSInstallCorequery in theunwanted-chrome-extensionspack that ships with osquery.
When analyzing results from this pack, we can assume that any result would be suspicious or have a higher likelihood of being a true positive. Thus, we can write the subsequent Panther rule:
The rule is analyzing that query results came from a query in the unwanted-chrome-extensions pack and the action is in the added state, meaning that new data was detected.
Analyzing query output
The second method of osquery log analysis is making a generic query, and using Python to further filter the output and identify something potentially suspicious.
For example, in the built-in incident-response pack for Linux, theres a crontab query:
And some example output:
Lets write a rule to detect a cron that loads something from /tmp/ (which is typical for malware):
This is just a simple implementation. The beauty of Python is that you can get as sophisticated as you would like. This includes using libraries like shlex to look deeper at the cron commands and much more.
Edge cases
There are a couple of caveats when writing rules on osquery data:
The first is that its entirely possible that we will miss certain activity between the query windows. One way around this limitation is to shorten the query window. The downside is that it has a potential performance hit, especially at scale. Another solution is to use tables that hook into process events.
The other caveat is that you may run into a situation where osquery is sending old logs, either from shell_history or last. One way around this limitation is by analyzing the epoch time, and making sure its within the last 24h or whatever your query window is set to (plus/minus about 30 minutes to account for splay + data landing in S3).
Share:





