
arrow-left
All Resources
Building a Detection & Response Team in a Cloud First Environment
Your company is growing and along with it your security team. You are looking to invest in a dedicated detection and response function (or take it from an early team to a maturing team). In this blog I will highlight a selected few challenges to keep an eye on and suggestions to address them as you build (or grow) a detection and response team and function.
Challenge 1: Going from an Early Stage to a Maturing Team
An early team is just starting to build out processes, may have some tooling in place, and is piggybacking on existing tooling investments. If you don't have one already, it's important to have an incident response plan to guide you when an incident does eventually happen. An easy-to-follow Incident Response (IR) plan is laid out here by Ryan McGeehan.
As your team matures, it will bring in dedicated Detection & Response (D&R) engineers so let's talk about hiring. Before you determine what profile to hire for, I think it's important to think about Detection and Response as an engineering function. I cover the importance of this more under Challenge 3: Setting up the Team to Scale in a Cloud-First Environment.
For the initial team members, focusing on hiring engineers with cross-functional experience in different security domains or adjacent to security domains (such as SRE) has worked well in my experience. Remember, that it's likely they will be sharing other responsibilities in a small security team. I'll cover this more in the next section.
Once the initial team is built out, the profile and the requirements can be adjusted to fill any specific gaps within the team or to bring on more junior engineers that can grow within the team / company. Geoff Belknap has a great post on how LinkedIn approached hiring to grow their security team.
Challenge 2: Managing a Broad Scope & Handling Shared Responsibilities
Depending on the organization, a D&R engineer's role may be broader than just writing detections and responding to alerts. Individuals on an early team are likely handling multiple things, but as the team and the company matures, you will find that things that could be someone's 15% job become someone's 100% job, and maybe eventually an entire team's job.
The D&R team itself will incorporate multiple functions as illustrated below:
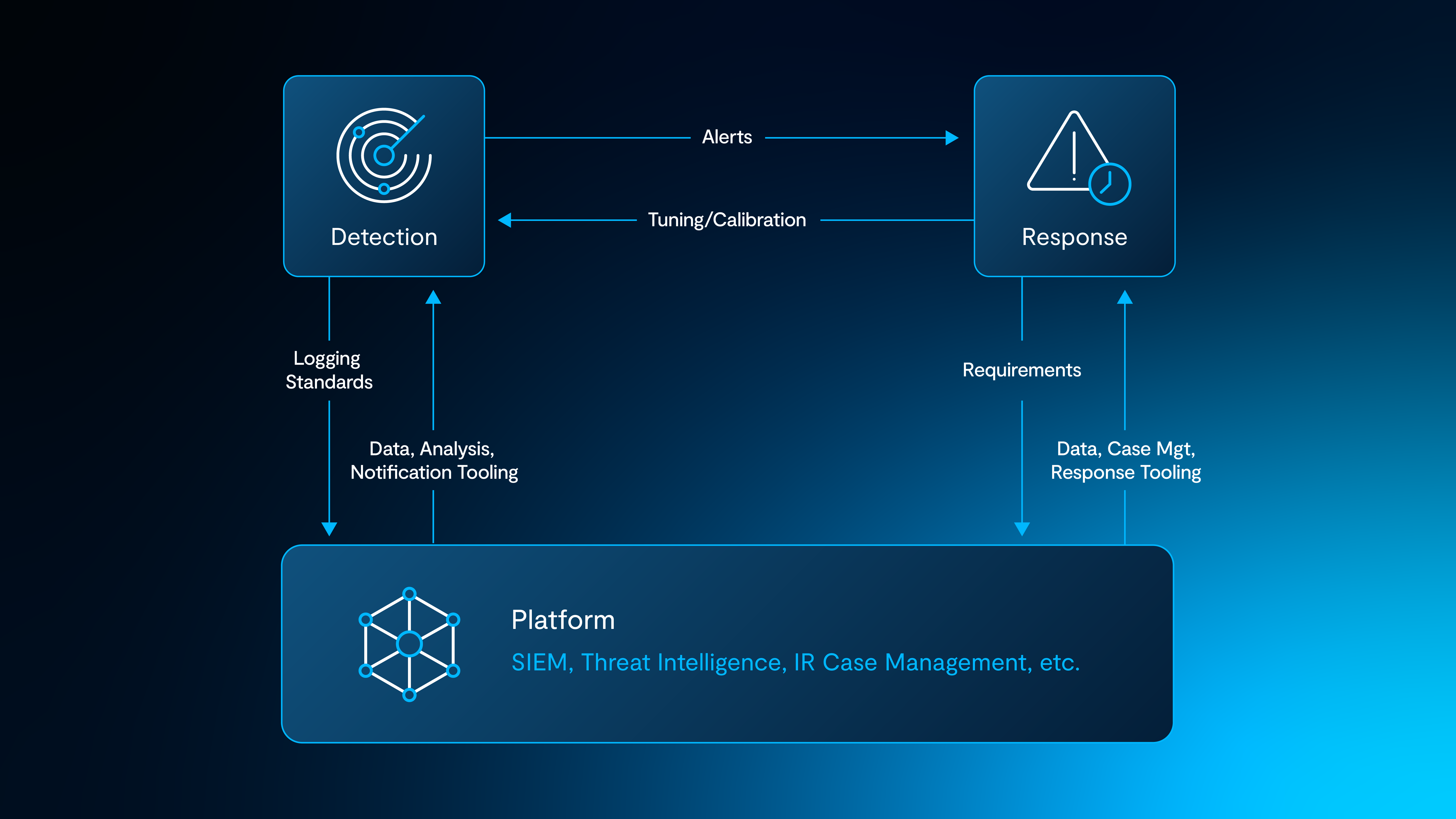
It's worth noting that with both Detection and Response as a single function, an engineer responding to alerts from the detection content they have created acts as a continuous motivator for creating and maintaining high fidelity detections. If the functions do end up separating, it'll be important to keep a tight alert Ui triage Ui tune feedback loop.
Challenge 3: Setting up the Team to Scale in a Cloud-First Environment
Companies are leveraging cloud services to build and scale their businesses faster than ever. As companies grow and the number of cloud services / SaaS providers grow, security teams will quickly find themselves outnumbered, and will be overwhelmed with data.
Approach Detection & Response as an engineering function, one which prioritizes automation. Focus on building a detection and response platform that doesn't overload the team with either low-fidelity alerts or manual overhead, and leverage standards such as unit testing and continuous visibility. This will help set the team up to scale as the organization, infrastructure, services, and data volumes grow.
One of our team's strategic operating principles is strive to shift-left and automate as much as possible'. This means two things in practice:
The first is to ship off alerts directly to the relevant teams and employees (as much as possible). This is true especially if an employee can confirm an action they took which resulted in an alert, or if they can provide faster context than a member of the security team. Panther's SlackBot is a good example of implementing this and expediting the response workflow bringing the security context into the tools where users already work.
The second is to automate. It's one of the lessons that our CEO Jack has covered in this blog post after speaking with multiple CISOs and security practitioners. A few key things to consider for automation are:
For the bullet point above, automate alert routing.
Pre-process alerts to enrich them with context and include the standard level of detail that a D&R engineer will expect.
Automate mitigation when possible. For example, a malware alert triggers an action to isolate the impacted machine.
Testing detections. Another lesson that Jack has covered in the blog post mentioned above is that Detection is becoming an engineering function. Taking the approach of a modern engineering team, automate testing of detection logic as well as testing the effectiveness of the detections.
This blog post further covers a few use cases for how we have (or can) leverage Panther and Tines to automate and scale Detection & Response.
Conclusion
There's a lot that goes into building a team and a function such that it scales in a cloud-first environment. While this blog doesn't cover all of the challenges you may face, a key takeaway that I'd double click on is to think about detection and response as an engineering problem. This will guide your team buildup, allow focus on solutions to not get buried with alerts and manual tasks, and importantly will help take care of the team.







